L'IA generativa è un tipo di Intelligenza Artificiale in grado di generare tutti i tipi di dati, inclusi audio, immagini, testo, simulazioni, oggetti 3D, video e così via. Prendendo ispirazione dai dati esistenti riesce a generare risultati nuovi e inaspettati, con ripercussioni nel mondo del design, dell'arte, ecc. Laddove ChatGPT è in grado di imitare uno scrittore umano, VALL-E fa lo stesso per la voce. Il sintetizzatore vocale VALL-E di Microsoft è in grado di imitare in modo convincente il modo di parlare di chiunque, fornendogli come esempio solo un campione audio di tre secondi. In questo articolo andremo ad indagare questa nuova applicazione delle reti neurali.
Introduzione
La tecnologia di sintesi vocale grazie all'uso di algoritmi di Deep Learning è diventata sempre più potente. Questi algoritmi utilizzano grandi quantità di dati vocali e imparano a imitare schemi e sfumature del linguaggio umano. Gli attuali sistemi di sintesi vocale da testo (TTS) sfruttano una pipeline con un modello acustico e un vocoder utilizzando spettrogrammi mel come rappresentazioni intermedie. Mentre, i sistemi TTS avanzati per poter sintetizzare discorsi di alta qualità da uno o più oratori, richiedono ancora dati puliti di alta qualità. Poiché i dati di addestramento sono relativamente piccoli, gli attuali sistemi TTS soffrono ancora di una scarsa generalizzazione. Ovvero, la somiglianza e la naturalezza del discorso sintetizzato diminuiscono drasticamente quando gli oratori non sono presenti nei dati di addestramento. I ricercatori di Microsoft hanno recentemente annunciato un nuovo sintetizzatore vocale chiamato VALL-E, addestrato su un enorme set di dati audio di alta qualità. Invece di progettare una rete complessa e specifica per il problema, la soluzione definitiva è stata quella di addestrare un modello con un ampio set dati, diversificati il più possibile. VALL-E è il primo framework TTS basato su un modello linguistico che sfrutta un ampio set di dati vocali, diversificato e multi-oratore. Sfruttando questi dati è stato dimostrato che non solo il modello è in grado di generare un discorso dal suono naturale, ma che è persino possibile imitare la voce di un nuovo oratore con uno stimolo di tre secondi di campione audio.
Funzionamento di VALL-E
Come mostrato nella Figura 1, per sintetizzare un discorso personalizzato, VALL-E genera i corrispondenti token acustici condizionati ai token acustici di una registrazione di 3 secondi e ai fonemi relativi allo stimolo testuale, che vincolano rispettivamente l'oratore e il contenuto informativo. Infine, i token acustici generati vengono utilizzati per sintetizzare la forma d'onda finale con il corrispondente decoder del codec audio neurale.
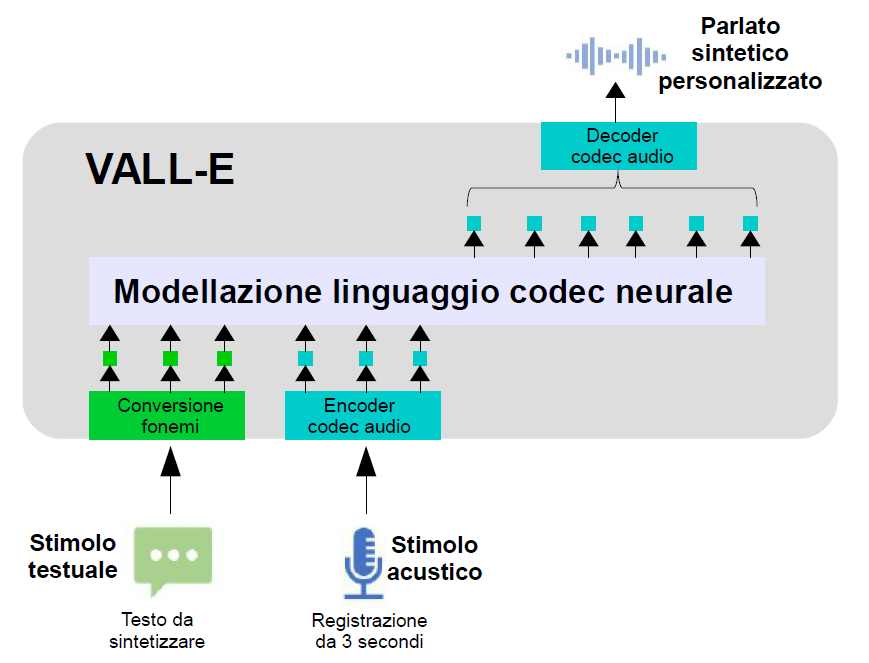
Figura 1: Panoramica di VALL-E
Codec audio neurali
I codec audio vengono utilizzati per comprimere in modo efficiente l'audio e ridurre così i requisiti di archiviazione o di larghezza di banda della rete. Idealmente, l'audio decodificato dovrebbe essere percettivamente indistinguibile dall'originale e il processo di codifica/decodifica non dovrebbe introdurre una latenza percepibile. Negli ultimi anni sono stati sviluppati con successo diversi codec audio per soddisfare questi requisiti. La qualità dell'audio ricostruito utilizzando questi codec risulta eccellente a bit rate medio-bassi, ma si degrada bruscamente quando si opera a bit rate molto bassi. Sebbene questi codec sfruttino la conoscenza profonda della percezione umana e pipeline di elaborazione del segnale attentamente progettate per massimizzare l'efficienza degli algoritmi di compressione, c'è stato un recente interesse a sostituire queste pipeline con approcci basati sull'apprendimento automatico che imparano a codificare l'audio in maniera "guidata dai dati". L'ingrediente tecnico principale di un codec audio guidato dai dati è una rete neurale, costituita da un codificatore, un decodificatore e un quantizzatore, tutti addestrati end-to-end. Il codificatore converte il flusso audio in ingresso in un segnale codificato, che viene compresso utilizzando il quantizzatore e quindi riconvertito in audio utilizzando il decodificatore. Un discriminatore calcola una combinazione di funzioni avversarie e di perdita da ricostruzione che inducono l'audio ricostruito a suonare come l'ingresso originale non compresso. Una volta addestrati, il codificatore e il decodificatore possono essere eseguiti su client separati per trasmettere in modo efficiente audio di alta qualità su una rete. Il codificatore produce vettori che possono assumere un numero indefinito di valori.
Per trasmetterli al ricevitore utilizzando un numero limitato di bit, è necessario sostituirli con i vettori più vicini presi da un insieme finito (chiamato codebook), un processo noto come quantizzazione vettoriale. Questo approccio funziona bene a bit rate bassi, ma raggiunge rapidamente i suoi limiti quando si utilizzano velocità più elevate. Ad esempio, anche a un bit rate di soli 3 kbps e supponendo che il codificatore produca 100 vettori al secondo, sarebbe necessario archiviare un codebook con più di 1 miliardo di vettori, cosa impossibile nella pratica. Un modo per aggirare questo problema è il quantizzatore vettoriale residuo (RVQ), costituito da diversi strati. Il primo livello quantizza i vettori di codice con una risoluzione moderata e ciascuno dei livelli successivi elabora l'errore residuo del precedente. Suddividendo il processo di quantizzazione in più livelli, la dimensione del codebook può essere ridotta drasticamente. Ad esempio, con 100 vettori al secondo a 3 kbps e utilizzando 5 livelli di quantizzatore, la dimensione del codebook passa da 1 miliardo a 320. Inoltre, è possibile aumentare o diminuire facilmente il bit-rate aggiungendo o rimuovendo livelli di quantizzatore, rispettivamente. VALL-E genera una serie di codici codec audio dal testo di stimolo e dal campione audio dell'oratore da imitare. L'algoritmo è quindi in grado, con l'aiuto dei dati di addestramento, di abbinare il modo di parlare dell'oratore con i campioni noti e generare un discorso simulato convincente. Il timbro vocale e il tono emotivo di chi parla, nei 3 secondi di stimolo, sono conservati nel discorso sintetico. VALL-E è stato addestrato con un corpus composto da 60.000 ore di parlato in inglese con oltre 7000 oratori unici. I dati originali sono solo audio, quindi è stato usato un modello di riconoscimento del parlato per generare le trascrizioni. I dati contengono così discorsi più rumorosi e trascrizioni imprecise ma forniscono diversi oratori e maggiori prosodie. Tale approccio è stato ritenuto robusto al rumore e in grado di meglio generalizzare sfruttando i dati di grandi dimensioni. Vale la pena notare che i sistemi TTS esistenti sono sempre stati addestrati con dozzine di ore di dati di un singolo oratore o centinaia di ore di dati di più oratori, cioè un numero più di cento volte inferiore.
EnCodec
Il modello neurale basato su codec audio, utilizzato da VALL-E come tokenizzatore, è il modello pre-addestrato EnCodec (una rete neurale per la compressione audio ad alta fedeltà) sviluppato da Meta e presentato ufficialmente nel 2022. EnCodec è un modello di codifica-decodifica convoluzionale, per il quale ingresso e uscita sono entrambi audio a 24 kHz con bit-rate variabile.
EnCodec è un'architettura basata su tre componenti principali:
- un codificatore (encoder) che accetta un estratto audio e restituisce una rappresentazione latente;
- uno strato di quantizzazione che produce una rappresentazione compressa tramite quantizzazione vettoriale;
- un decodificatore (decoder) che ricostruisce il segnale nel dominio del tempo dalla rappresentazione latente compressa.
L'encoder produce incorporamenti (spazi di dimensioni relativamente basse in cui si possono tradurre vettori di dimensioni elevate) a 75 Hz per forme d'onda in ingresso a 24 kHz, portando ad una riduzione della frequenza di campionamento di 320 volte. Ogni incorporamento è modellato da un vettore residuo di quantizzazione (RVQ); vi sono otto quantizzatori gerarchici con 1024 voci ciascuno come raffigurato nella Figura 2. Questa configurazione corrisponde a EnCodec per la ricostruzione audio a 24 kHz con bit rate pari a 6 kbps. In questa configurazione, data una forma d'onda di 10 secondi, la rappresentazione discreta è una matrice con 750x8 voci, dove 750 = (24000x10)/320 è il passo temporale sottocampionato e 8 è il numero di quantizzatori. Un bit rate maggiore corrisponde a più quantizzatori e migliore qualità della ricostruzione. Ad esempio, se scegliamo EnCodec a 12 kbps di bit rate, sono necessari 16 quantizzatori e la forma d'onda di 10 secondi corrisponde a una matrice con 750x16 voci.
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 1951 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.