
L'apprendimento automatico (machine learning) è un processo iterativo che richiede l'utilizzo di molti strumenti, programmi e script diversi per ogni fase. Un workbench (banco di lavoro) per l'apprendimento automatico è una piattaforma o un ambiente che supporta e facilita una serie di attività per l'apprendimento automatico riducendo o eliminando la necessità di più strumenti. In questo articolo andremo ad introdurre Weka, un workbench open source per l'apprendimento automatico che può permettere anche ai neofiti di avvicinarsi fin da subito al mondo del machine learning.
Introduzione
Weka è un acronimo che sta per Waikato Environment for Knowledge Analysis. Entrando nel dettaglio, Weka è un software per l'apprendimento automatico sviluppato nell'università di Waikato in Nuova Zelanda, è open source e viene distribuito con licenza GNU General Public License. Curiosamente la sigla corrisponde proprio al nome di un simpatico animale simile al Kiwi, presente solo nelle isole della Nuova Zelanda. La scelta di parlare di Weka in questo articolo può essere riassunta nelle cinque caratteristiche di seguito descritte che lo rendono così interessante:
- Open Source: il fatto che sia rilasciato come software open source sotto licenza GNU GPL, lo rende di facile accesso per tutti
- Interfaccia grafica: presenta un'interfaccia grafica utente (GUI), il che consente di completare i progetti di apprendimento automatico senza la necessità di conoscere concetti di programmazione
- Interfaccia a riga di comando: tutte le funzioni del software possono essere utilizzate dalla riga di comando. Questo può essere molto utile per lo scripting di lavori di grandi dimensioni
- API Java: Weka è scritto in Java e fornisce un'API ben documentata che promuove l'integrazione nelle applicazioni
- Documentazione: ci sono libri, manuali, wiki e corsi che possono insegnare come utilizzare la piattaforma in modo efficace
La filosofia che risiede dietro la creazione di Weka è quella per cui, quando si inizia con l'apprendimento automatico applicato, ci sono molte cose da imparare, come ad esempio algoritmi, dati, statistica, lo strumento che si prevede di usare. Spesso bisogna imparare un nuovo linguaggio di programmazione, quale Python o altri linguaggi esoterici come Matlab o R. Allora invece di provare e forse non riuscire ad imparare una miriade di cose nuove, perchè non focalizzare l'attenzione sulla sola cosa importante, ovvero come consegnare un risultato. Weka propone all'utente di imparare come fornire un risultato nell'apprendimento automatico applicato utilizzando un processo sistematico. Tale processo si compone di 5 passi:
- Definizione del problema
- Preparazione dei dati
- Valutazione di una suite di algoritmi
- Miglioramento dei risultati
- Finalizzazione del modello e presentazione dei risultati
Weka supporta le tre principali piattaforme: Windows, OS X e Linux. Andando sul sito ufficiale di Weka è possibile scaricare la distribuzione appropriata per il proprio sistema operativo. Weka necessita che sul computer vi sia la presenza di una Java VM, se così non fosse, sul sito di Weka sono presenti degli eseguibili che includono sia Weka 3.8 sia JavaVM 1.8. Una volta installato basterà cliccare sull'icona simile ad un uccello per avviare il programma. Prima di entrare nel dettaglio, occorre sottolineare che nell'articolo si daranno per scontati molti concetti chiave del machine learning. Per chi volesse affrontare l'argomento senza alcuna conoscenza a riguardo, consigliamo di leggere alcuni lavori precedentemente pubblicati sul blog così da avere almeno un'infarinatura iniziale.
Weka GUI Chooser
Il punto di ingresso nell'interfaccia di Weka è la scelta della GUI di Weka. È un'interfaccia che consente di scegliere e avviare uno specifico ambiente Weka (figura 1).
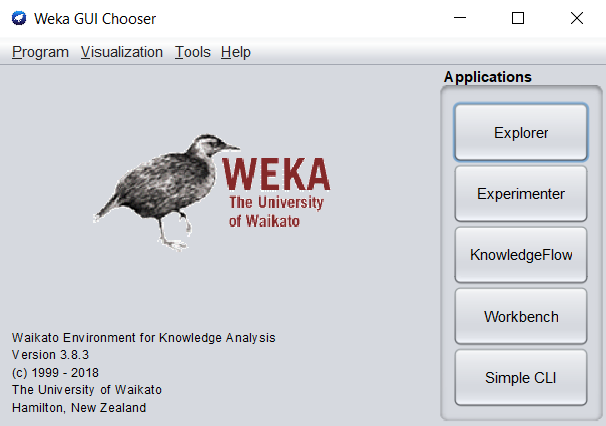
Figura 1. La Weka GUI Chooser
Oltre a fornire l'accesso agli strumenti di base di Weka, presenta anche una serie di utility e strumenti aggiuntivi forniti nel menu. Ci sono due funzioni degne di nota nel menu a tendina "Tool": il Package manager che consente di cercare e installare componenti aggiuntivi di terze parti su Weka come nuovi algoritmi e ARFF-Viewer che permette di caricare e trasformare set di dati e salvarli in formato ARFF. Weka è progettato per caricare i dati in un formato nativo chiamato ARFF. È un formato CSV modificato che include informazioni aggiuntive sui tipi di ciascun attributo (colonna). Weka supporta anche il caricamento dei dati da file CSV così come da database e la possibilità di convertirli in ARFF a seconda delle necessità. Inoltre Weka offre tre ambienti di lavoro specifici: Explorer per giocare con i dati e analizzarli, Experimenter per esperimenti controllati e KnowledgeFlow per la progettazione grafica di una pipeline per il proprio problema. In questo articolo andremo ad analizzare la modalità Explorer, lasciando le altre da approfondire in successivi lavori.
Weka Explorer
Weka Explorer è il luogo ideale in cui giocare con i dati e pensare a quali trasformazioni applicare loro, quali algoritmi eseguire negli esperimenti. È utile quando si sta pensando a diverse trasformazioni di dati e algoritmi di modellazione che si potrebbero studiare con un esperimento controllato in seguito. È eccellente per raccogliere idee e giocare a scenari ipotetici.
L'interfaccia di Explorer è divisa in 6 diverse schede o tabelle:
- Preprocess: per caricare un set di dati e manipolare i dati in un modulo con cui si vuol lavorare
- Classify: per selezionare ed eseguire algoritmi di classificazione e regressione ed operare sui dati
- Cluster: per selezionare ed eseguire algoritmi di clustering sul set di dati
- Associate: per eseguire algoritmi di associazione per estrarre informazioni dai dati
- Select attributes: per eseguire algoritmi di selezione degli attributi sui dati e selezionare quegli attributi che sono rilevanti per la desiderata funzione
- Visualize: per visualizzare la relazione tra gli attributi
La scheda Preprocess serve per caricare il set di dati e applicare i filtri per trasformare i dati in una forma che esponga meglio la struttura del problema ai processi di modellazione. Fornisce anche alcune statistiche riassuntive sui dati caricati.
La scheda Classify serve per la formazione e la valutazione delle prestazioni di diversi algoritmi di apprendimento automatico sul problema di classificazione o regressione. Gli algoritmi sono suddivisi in gruppi, i risultati vengono mantenuti in un elenco di risultati e riepilogati nell'output principale del classificatore.
La scheda Cluster serve per la formazione e la valutazione delle prestazioni di diversi algoritmi di clustering non supervisionati sul set di dati senza etichetta. Gli algoritmi sono divisi in gruppi, i risultati vengono mantenuti in un elenco di risultati e riepilogati nell'output principale.
La scheda Associate consente di trovare automaticamente le associazioni in un set di dati. Le tecniche sono spesso utilizzate per problemi di data mining di analisi del paniere di mercato e richiedono dati in cui tutti gli attributi sono categorie.
La scheda Select attributes consente di eseguire la selezione delle funzioni sul set di dati caricato e di identificare quelle funzioni che sono più probabili essere rilevanti nello sviluppo di un modello predittivo.
La scheda Visualize è per la revisione della matrice del diagramma a dispersione a coppie di ciascun attributo tracciato rispetto ad ogni altro attributo nel set di dati caricato. È utile avere un'idea della forma e della relazione degli attributi che possono aiutare nel filtraggio, nella trasformazione e nella modellazione dei dati.
Facciamo un esempio
Attraverso un esempio pratico risulterà forse più semplice l'analisi delle tante funzioni del tool. L'installazione di Weka include una sottodirectory con un certo numero di dataset per l'apprendimento automatico nel formato ARFF pronti per essere caricati. Nella tabella Preprocess si prema il tasto "Open file" e si selezioni diabetes.arff dalla directory data presente nella cartella di installazione (nel mio caso il percorso è il seguente C:\Program Files\Weka-3-8\data). Si tratta di un problema di classificazione binaria. Il dataset (diabetes.arff) è stato utilizzato in passato per prevedere l'insorgenza del diabete mellito per mezzo di un algoritmo. In sostanza occorreva [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2117 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Creazione di una rete ESP-Mesh in pochi passi

Edge Computing: l’apprendimento automatico ai confini della rete
Controllo IoT dell’illuminazione con Alexa e il microcontrollore Wi-Fi ESP8266 – Parte 1

Progetto di un Chatbot IA con NLP e Python – Puntata 1
