
Le configurazioni monolitiche hanno da tempo lasciato la mano per le nuove architetture modulari. In questo particolare contesto le soluzioni basate su infrastrutture, quali la distribuzione dei dati, stanno acquisendo un ruolo importante.
In un contesto embedded di tipo real time a volte è necessario stabilire un compromesso perché soluzioni di questo tipo ben si adattano ad applicazioni di tipo generale. In effetti, in applicazioni basate sulla distribuzione dei dati è necessario garantire altri fattori, quali la dimensione delle applicazioni o l’integrazione dei sistemi eterogenei, garantendo requisiti di timeliness, fault-tolerance, scalabilità. Il protocollo Real Time Publish Subscribe (RTPS) può rappresentare una buona soluzione. Infatti, la distribuzione delle risorse è certamente una necessità sempre più stringente perché consente di garantire alcuni paradigmi al fine di assicurare l’interoperabilità di un’applicazione. Una soluzione di questo tipo introduce, però, un nuovo approccio perché costringe a definire un nuovo sistema architetturale rispetto al passato. Con il termine Cloud Computing e il concetto di collaborazione tra sistemi distribuiti ed eterogenei, è possibile introdurre tecnologie quali il Web Service, SOAP, XML e HTTP che permettono di garantire la scalabilità e una rappresentazione dei dati e delle funzioni quanto più semplice possibile.
Nel particolare segmento di mercato dell’embedded, questi modelli architetturali non sono del tutto applicabili perché devono calarsi in una situazione assolutamente particolare per soddisfare requisiti più stringenti, quali il determinismo delle operazioni o l’affidabilità delle informazioni scambiate. L’esigenza di avere applicazioni distribuite in ambienti di larga scala, scalabili e affidabili, ha portato alla creazione di nuovi paradigmi di comunicazione. L’unico in grado di fornire la disseminazione delle informazioni in forma anonima, in maniera asincrona, garantendo il totale disaccoppiamento dei partecipanti, è il paradigma publish/subscribe: i partecipanti non devono conoscersi reciprocamente, mentre le operazioni d’invio e ricezione non devono essere sincronizzate e non è necessario che le entità interessate siano attive nello stesso tempo.
Il modello publish/subscribe è particolarmente adatto alla realizzazione di applicazioni distribuite aventi come task principale la distribuzione dei dati. I middleware basati su questo paradigma sono in grado di offrire un elevato livello di disaccoppiamento tra le entità comunicanti rendendo particolarmente agevole la realizzazione di schemi di comunicazione molti-a-molti anche con requisiti di tempo stringenti, come nel caso di sistemi real-time e mission critical, oltre a un elevato grado di scalabilità al crescere dei partecipanti alla comunicazione. Non solo, il paradigma publish/subscribe si presta a differenti implementazioni; infatti esistono soluzioni basate sul modello client/server.
MIDDLEWARE
Il middleware è uno strato software interposto tra il sistema operativo e le applicazioni, in grado di fornire astrazioni e servizi utili per lo sviluppo di applicazioni distribuite, così da consentire di interoperare indipendentemente da possibili eterogeneità. Un middleware, al solito, si classifica in base ai servizi che è in grado di offrire alle applicazioni presenti. Si parte dal modello RPC-based e in questo caso si prevedono le infrastrutture necessarie per eseguire le RPC in modo trasparente al programma e in modo uniforme rispetto ai protocolli sottostanti. Al contrario, con l’object-broker si riesce a estendere il paradigma RPC con l’aggiunta di numerosi servizi che semplificano lo sviluppo di applicazioni distribuite secondo il paradigma object-oriented, mentre con il message-oriented si vogliono identificare middleware che si basano sullo scambio di messaggi, ovvero insieme di dati strutturati, caratterizzati da un tipo e un insieme di parametri del messaggio. Infine, ma non ultimo, esiste anche il cosiddetto message-brokers: un paradigma che si occupa dello scambio di messaggi in una rete di telecomunicazioni con uno schema di indirizzamento non più punto-punto ma con un indirizzamento orientato ai messaggi: il paradigma più noto è il publish/subscribe.
SERVICE ORIENTED ARCHITECTURE (SOA)
Il Service Oriented Architecture (SOA) si basa sul concetto di servizio. Un servizio è una funzionalità offerta dal sistema che viene incapsulata, nel nostro caso, all’interno di un’apposita interfaccia. Questa è poi utilizzata per effettuare chiamate a una risorsa dall’interno di una generica applicazione o attraverso una rete abilitata alla connessione. In un sistema di questo tipo, un servizio è offerto in base a un service contract, ovvero ricorrendo a una sorta di promessa del servizio allo scopo di offrire le funzionalità in maniera specifica e affidabile. Ogni servizio, in questo contesto, utilizza un service registries che permette, una volta registrato il servizio stesso, di esportarlo alle altre applicazioni attraverso la rete. In un contesto Web Services, non del tutto applicabile in un tipico sistema embedded, allo scopo di definire e pubblicare l’interfaccia del servizio e, di conseguenza, esportarla agli utenti della rete, gli sviluppatori utilizzano il Web Service Description Language (WSDL). WSDL è un modello basato su XML che consente a un’applicazione di definire il meccanismo di comunicazione per sfruttare così il servizio disponibile. La descrizione WSDL può essere utilizzata per costruire un messaggio in ambito SOAP, o Service Oriented Architecture Protocol (SOAP): questo protocollo è, di fatto, il mezzo più utilizzato di messaggistica per i servizi.
Utilizzare un’architettura SOA consente diversi vantaggi. In SOA è presente, ad esempio, il concetto del riuso delle funzionalità tra le applicazioni o l’incapsulamento che permette di nascondere i dettagli della singola realizzazione ai moduli che richiedono il servizio. Così, l’autore del servizio che gestisce le informazioni su un’ipotetica linea hardware deve conoscere la struttura del database utilizzato al fine di memorizzare le informazioni in modo corretto. In questo contesto le applicazioni che chiamano il gestore del modulo hardware non devono, a loro volta, conoscere nulla della risorsa perché accedono solo all’interfaccia. Non solo, al solito le implementazioni SOA risultano del tipo loosely coupled. Gli agenti in un sistema distribuito, non operando nello stesso ambiente, devono comunicare affidandosi a protocolli software e hardware attraverso una rete: questo implica che le comunicazioni in un sistema di questo tipo sono intrinsecamente meno veloci e disponibili di quelle effettuate attraverso invocazioni dirette nel codice utilizzando memoria condivisa. Certamente una gestione di questo tipo offre importanti implicazioni architetturali, poiché i sistemi distribuiti richiedono che gli sviluppatori prendano in considerazione l’imprevedibile latenza di una comunicazione remota e gestiscano le problematiche derivate dalla concorrenza.
Ricordiamo che i distributed object systems sono sistemi nei quali la semantica dell’inizializzazione di un oggetto, e dei suoi metodi, sono esposti a definizioni remote tramite meccanismi proprietari o standard, al fine di inviare la richiesta oltre i confini del sistema per mezzo del marshall o unmarshall degli argomenti dei metodi. Ricordiamo che una Service Oriented Architecture (SOA) è un tipico schema architetturale di sistemi distribuiti caratterizzato da alcune proprietà come l’orientamento alla connessione e ai messaggi. Infatti, nella SOA il servizio è definito in termini di messaggi scambiati tra l’agente fornitore e l’agente fruitore e non sulle proprietà degli agenti stessi. La struttura interna degli agenti è deliberatamente astratta nella SOA perché non è necessario conoscere il dettaglio della sua implementazione. In ambito embedded è possibile ricorrere a un’architettura del tipo event driven. Con questo concetto si vuole definire un paradigma software per la produzione, gestione, utilizzo e reazione agli eventi. In questo contesto per evento si deve intendere una significativa modifica del suo stato: il sistema di gestione degli stati può trattare questo cambio come un evento da raccogliere, segnalare e far processare dalle varie applicazioni presenti nell’architettura.
POSSIBILE REALIZZAZIONE
In un sistema embedded una delle possibili realizzazioni di un ambiente distribuito è senz’altro un modello publish/subscribe con un meccanismo di comunicazione HTTP che consente ai diversi client presenti di memorizzare anche il contenuto delle informazioni con il relativo stato. Il progetto è open source ed è identificato come open-rtps e, nella versione 02, sfrutta il protocollo HTTP o, per la precisione, un suo sottoinsieme. La versione 02 dell’applicazione è stata realizzata e provata su una evaluation board di Cayonlands (Figura 3) basata su PowerPc con IP 10.60.90.200. L’applicazione comunica sulla porta 8080 con un protocollo che richiede una formattazione del tipo
GET http:// 10.60.90.200:8080/ID
dove con ID si identifica la richiesta, così come pongono in evidenza le Figure 1 e 2. La Figura 1 mostra la richiesta dello stato della scheda, effettuata da un PC presente nella rete utilizzando un browser, mentre la Figura 2 pone in evidenza la stessa richiesta utilizzando un client dedicato. È in fase di stesura la prossima versione che prevede di implementare un diverso meccanismo di comunicazione, sfruttando sempre l’applicazione HTTP ma ricorrendo anche a politiche di real time Ethernet.
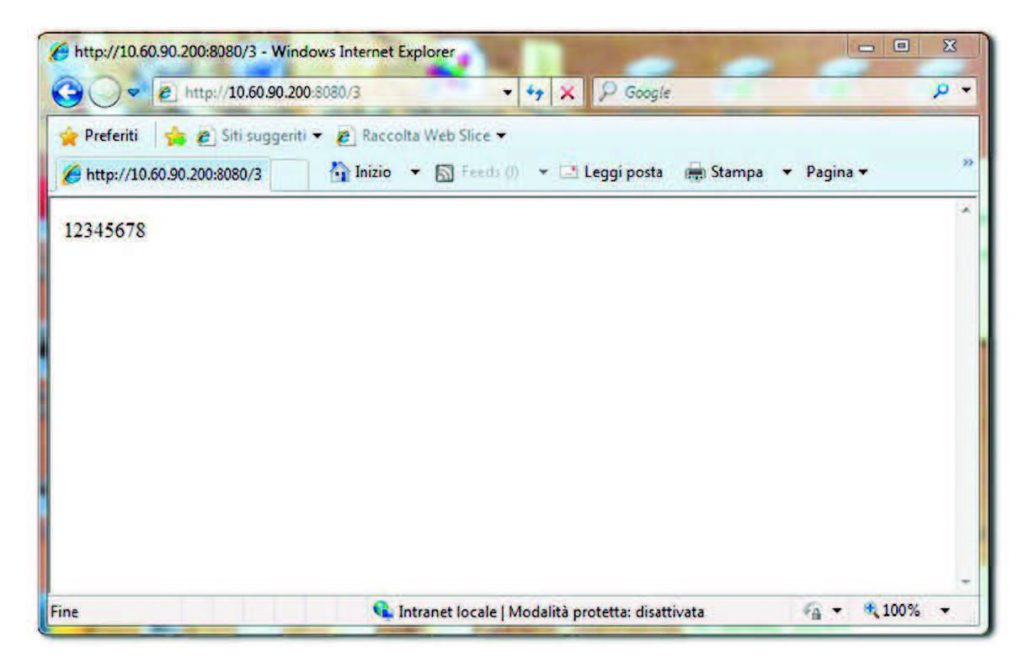
Figura 1: connessione con browser web
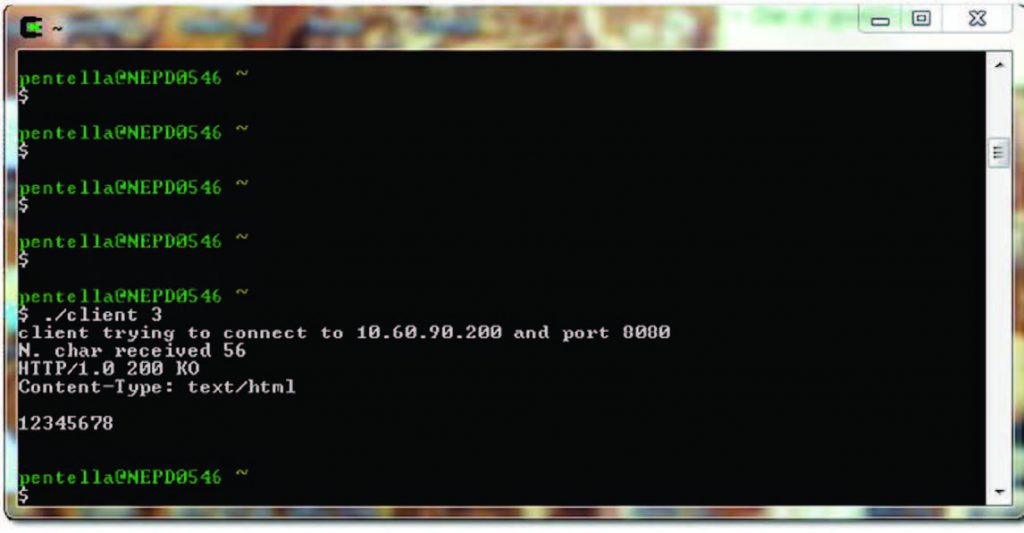
Figura 2: client dedicato
AFFIDABILITÀ E DETERMINISMO
Le applicazioni real time richiedono, infatti, funzioni quali, ad esempio, il controllo dei tempi di consegna (Delivery Timing Control) assieme al controllo della validità del dato, oltre alla possibilità di richiedere una consegna affidabile dei dati (Reliability Control) e a una semantica “request-reply”. Infatti, le applicazioni real time complesse, spesso, non si sposano perfettamente con la misura della semantica publish-subscribe. Non solo, può essere indispensabile utilizzare una banda per la consegna del dato più flessibile possibile, flexible delivery bandwidth, fornendo ai subscribers la possibilità di richiedere diversi valori per la consegna anche della stessa pubblicazione assieme a una tolleranza a malfunzionamenti della rete (fault tolerance), garantendo, alle applicazioni publisher e subscriber, il cosiddetto hot standby e una thread priority awareness. In questi particolari contesti è anche necessario utilizzare un livello di trasporto del tipo multicast e connectionless best-effort come l’UDP/IP. A questo scopo può essere utile implementare il protocollo, o parti di esso, RTPS (Real Time Publish Subscribe). Infatti, questo protocollo è stato progettato in maniera tale da soddisfare requisiti indispensabili, per i quali il paradigma publish-subscribe non offre il supporto. In questo contesto diventa così possibile realizzare meccanismi di fault tolerance allo scopo di permettere la creazione di reti di comunicazioni prive di “single points of failure” o di QoS per realizzare, su reti IP standard, il “best effort” e le comunicazioni “reliable” per applicazioni real time che saranno presenti nella prossima versione.
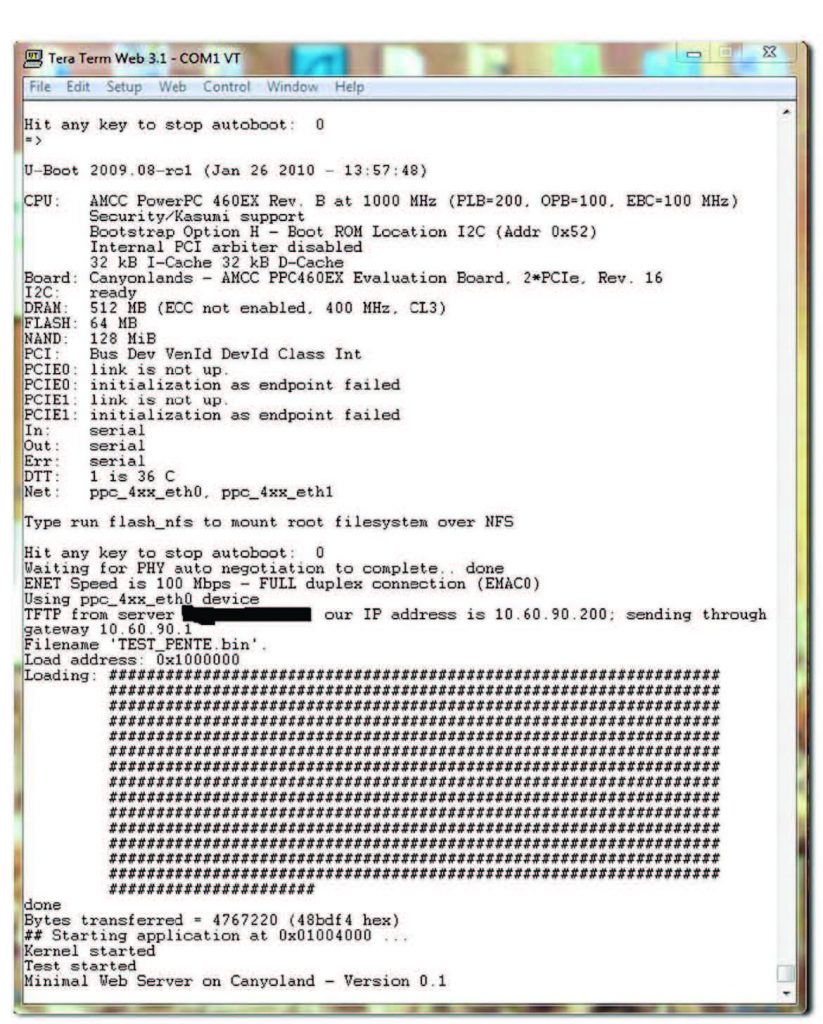
Figura 3: startup EVB
CONCLUSIONE
Il progetto è open source e ha l’obiettivo di offrire un middleware per sistemi embedded. Al momento non è disponibile una versione portabile, ma dalla versione 03 può essere provato, senza particolari problemi, su differenti architetture hardware di tipo embedded quali MSP430 o ARM.

