
Il Coldfire TCSP/IP stack è una sorgente pubblica di comunicazione in linea con i microprocessori. Lo stack è molto robusto e facilmente configurabile. Supporta molti comuni protocolli di comunicazione e include molti esempi di applicazioni. Vediamo alcune caratteristiche.
Il Freescale/NXP ColdFire è un microprocessore della famiglia 68k concepito per sistemi embedded prodotto da Freescale Semiconductor/NXP. Il set di istruzioni del ColdFire è compatibile al livello di sorgente “assembly” (tramite un software di traduzione disponibile presso il fornitore) ma non è totalmente compatibile a livello di codice oggetto con il 68000. Rispetto al classico hardware 68k, il set di istruzioni differisce principalmente per il fatto che sono state rimosse alcune istruzioni poco usate, come quelle a supporto del formato dati BCD; inoltre la maggior parte delle istruzioni rimaste supporta un numero ridotto di modi d’indirizzamento. Questo ha verosimilmente consentito di ridurre la complessità ed il costo dell’unità di decodifica delle istruzioni. Anche la dimensione dei registri in virgola mobile cambia, riducendosi a 64 bit invece degli 80 del 68881 e del 68882. I nuovi modelli del ColdFire sono sufficientemente compatibili con i processori della famiglia 68000, al punto che adesso è possibile creare cloni Amiga compatibili al livello di codice eseguibile. Il progetto Debian sta lavorando per estendere ai processori ColdFire la compatibilità del suo port m68k, in quanto alcuni modelli di ColdFire sono molto più veloci del 68060. Il loro clock può raggiungere anche i 300MHz, rispetto ai 60MHz dei 68060 (il più veloce “genuino” processore m68k) senza overclocking.
ColdFire TCP/IP
Il protocollo TCP/IP (Transmission Control Protocol e Inter net Protocol) è un insieme standard di protocolli sviluppato nella seconda metà degli anni ‘70 dalla DARPA (Defence Advanced Research Project Agency), allo scopo di permettere la comunicazione tra diversi tipi di computer e di reti di computer. TCP/IP è il motore di Internet, ecco perchè è l’insieme di protocolli di rete più diffuso al mondo. I due protocolli che compongono il TCP/IP si occupano di aspetti diversi delle reti di computer. L’Internet Protocol, la parte IP di TCP/IP, è un protocollo senza connessione che tratta solo l’instradamento dei pacchetti di rete usando il datagramma IP come l’unità fondamentale dell’informazione di rete. Il datagramma IP è formato da un’intestazione seguita da un messaggio. Il Transmission Control Protocol, la parte TCP di TCP/IP, consente agli host della rete di stabilire delle connessioni usate per scambiare flussi di dati. Inoltre il TCP garantisce che i dati tra le connessioni siano consegnati e che arrivino ad host della rete nello stesso ordine in cui sono stati trasmessi da un altro host della rete. ColdFire TCP/IP possiede le seguenti proprietà:
- protocollo http server e client
- RSS/XML client
- TCP/UDP client e server
- TFTP
- Protocollo internet IP Protocollo DHCP
ll ColdFire TCSP/IP include inoltre protocolli per dispositivi embedded network. (figura 1).
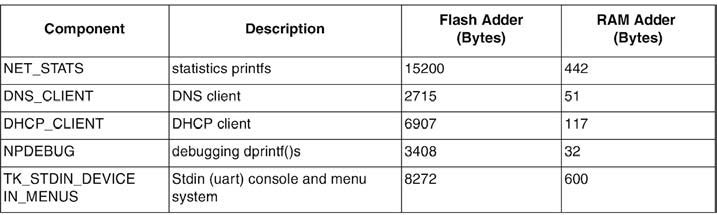
Figura 1: componenti dello stack TCP/IP.
Il progetto ColdFire TCS/IP usa 3 tipi di RAM (figura 2).
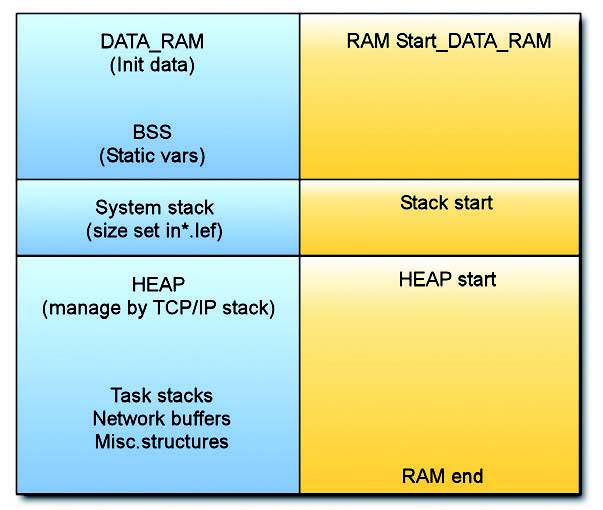
Figura 2: modello della memoria TCP/IP.
Il BSS è assegnato da un linker. Questa RAM contiene le variabili globali ed è considerata statica. Il sistema è definitio da un linker, specificato nel file di progetto definito come *.lcf. Il sistema è hard-coded. Il HEAP è gestito dal ColdFire TCP/IP ed è anche usato dallo stack TCP/IP per storage temporaneo, buffer di network (figura 3).
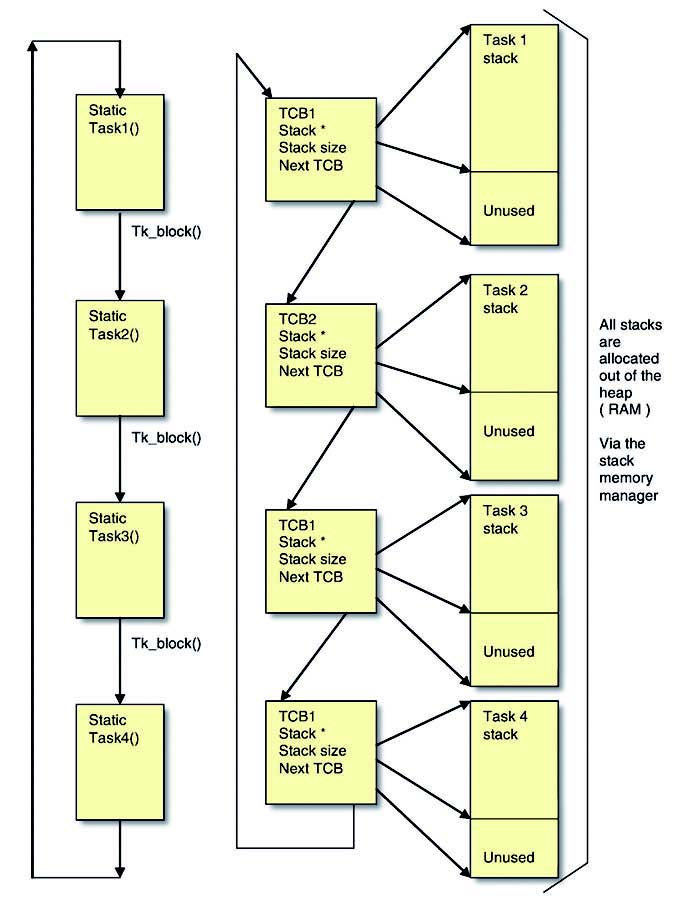
Figura 3: allocazione della memoria ColdFire TCP/IP.
HEAP – Task Stacks
Un heap (figura 4) è una struttura dati utilizzata in informatica, più precisamente un albero binario quasi completo usato principalmente per la memorizzazione di collezioni di dati, dette dizionari.
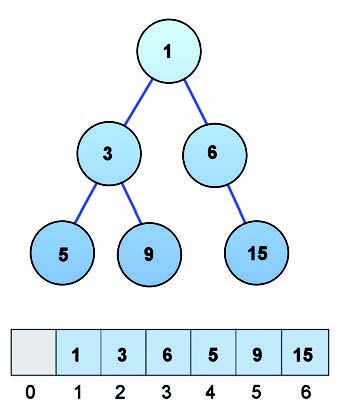
Figura 4: memoria Heap.
In ogni nodo è presente una coppia (k,x) in cui k è il valore della chiave associata alla entry x. Nei dizionari, a differenza delle mappe, ogni chiave può essere associata a più entry (come in un “reale” dizionario ogni parola ha più significati). Questi tipi di albero hanno la seguente caratteristica: qualsiasi nodo padre ha chiave minore di entrambi (se esistono) i suoi figli. In questo modo si garantisce che compiendo un qualsiasi percorso che parte da un nodo v dell’albero e scendendo nella struttura verso le foglie, si attraversano nodi con chiave sempre crescente (in senso lato). Nell’allocazione di memoria basata su heap, la memoria è allocata da un grande blocco di memoria inutilizzata chiamato heap (che non ha nulla a che vedere con l’omonima struttura dati, ma ha a che fare col significato gergale della parola “una grande quantità di qualcosa”). La dimensione della memoria da allocare può essere determinata a runtime e la durata di vita dell’allocazione stessa non dipende dalla procedura o dallo stack frame correnti. Si accede per via indiretta alla regione di memoria allocata, in genere attraverso un riferimento. L’esatto algoritmo utilizzato per organizzare l’area di memoria e le operazioni di allocazione/deallocazione viene in genere nascosto dietro un’interfaccia astratta (information hiding) e potrebbe usare uno qualsiasi dei metodi elencati in precedenza. In contrasto, la memoria dello stack delle chiamate è normalmente di dimensione limitata e la durata di vita delle allocazioni dipende dalla durata delle corrispondenti funzioni.
Call stack
L’allocazione dinamica della memoria avviene generalmente attraverso la funzione malloc(), oppure calloc(), definite nella libreria standard stdlib.h. Se queste riescono a eseguire l’operazione, restituiscono il puntatore alla memoria allocata, altrimenti restituiscono il valore NULL.
void *malloc (size_t dimensione);
void *calloc (size_t quantità,
size_t dimensione);
La differenza tra le due funzioni sta nel fatto che la prima, malloc(), viene utilizzata per allocare un’area di una certa dimensione, espressa generalmente in byte, mentre la seconda, calloc(), permette di indicare una quantità di elementi e si presta per l’allocazione di array. Dovendo utilizzare queste funzioni per allocare della memoria, è necessario conoscere la dimensione dei tipi primitivi di dati, ma per evitare incompatibilità conviene farsi aiutare dall’operatore sizeof. Il valore restituito da queste funzioni è di tipo void * cioè una specie di puntatore neutro, indipendente dal tipo di dati da utilizzare. Per questo, in linea di principio, prima di assegnare a un puntatore il risultato dell’esecuzione di queste funzioni di allocazione, è opportuno eseguire un cast.



Il processore Coldfire, inizialmente sviluppato da Motorola/Freescale e ora curato da NXP, rappresenta un buon compromesso tra caratteristiche tipiche di un RISC ed elevata densità del codice. Inoltre, è quasi completamente compatibile, a livello di instruction set, con la famiglia 680×0.
Se 40 anni fa c’era l’8086, mi domando tra 40 anni cosa ci sarà…
Bella domanda…useremo chip fotonici?