
Per una persona, “riconoscere un oggetto” è un processo così automatico che, se dovessimo chiedere a qualcuno “come si fa”, probabilmente dovrebbe pensarci un pò prima di riuscire a dare una risposta. Ma, a voler stringere, possiamo dire che si tratta di un processo in due fasi: prima di tutto, dobbiamo vederne un pò di questi oggetti, e poi dobbiamo riuscire ad estrarre da essi qualche caratteristica unica, che ci permetta appunto di distinguerli da tutti gli altri che li assomigliano. Un capriolo è diverso da un cervo perché è più piccolo, ha le corna fatte in un altro modo e ha una macchia di pelo bianco sul sedere. Un computer, per poter riconoscere un oggetto, ha bisogno delle stesse cose: di vederlo più volte (molte di più di una persona), e di riuscire ad estrarre alcune sue features distintive. Di come si possano estrarre queste features è ciò di cui vi parleremo oggi.
MELE E ARANCE

Figura 1: Tazze e ciambelle
Una tristissima battuta a tema matematico vuole che il topologo sia quella persona incapace di distinguere una tazza di caffè da una ciambella. Questo perché la topologia è quella branca della matematica che considera equivalenti tutti quegli oggetti che, se fossero fatti di plastilina, potrebbero essere deformati l’uno nell’altro senza mai romperli. E, come si vede nella Figura 1, questo è esattamente ciò che si può fare per una tazzina e una ciambella. Ma, sempre per un topologo, una ciambella e una mela non sono equivalenti, per il banale motivo che la mela non ha buchi.
Sì, l’abbiamo presa un pò alla larga, ma la topologia è un ottimo esempio dell’incredibile capacità di astrazione di cui siamo dotati. Il buco è, in fin dei conti, l’unica caratteristica essenziale che distingue una ciambella da una mela. Ma questo non è sufficiente per distinguere, ad esempio, una mela da una banana: ci vuole qualche altra caratteristica, ad esempio il fatto che la mela è tonda e la banana allungata. Ma questo a sua volta non è sufficiente per distinguere una mela da un’arancia, che sono entrambe tonde. Bisogna aggiungere il fatto che le mele non sono esattamente tonde, ma hanno l’incavatura in alto con il picciolo, mentre le arance questa incavatura non ce l’hanno. E potremmo continuare. Per noi è piuttosto semplice osservare un oggetto ed estrarre le sue caratteristiche fondamentali, e quando dobbiamo decidere se quell'oggetto tondo che abbiamo in mano è una mela o un’arancia, possiamo usare queste caratteristiche per farlo. Se abbiamo sempre mangiato mele Golden, non sarà difficile riconoscere una mela Fuji: la forma è quella, all’incirca, cambia solo un pò il colore. E ci riusciamo perché abbiamo capito cos’è che rende “mela” una mela.
Ci riusciamo piuttosto bene perché, senza rendercene conto, le caratteristiche che estraiamo sono anche invarianti. “Invarianti” significa che, se modifichiamo un pò l’oggetto, queste caratteristiche rimangono le stesse; non variano, per l’appunto. Una mela renetta in genere è più piccola di una Golden, ma possiamo comunque dire che è una mela, perché la forma è quella, solo più in piccolo. Lo stesso se la mela fosse stata messa a testa in giù.
Tutto questo, per un computer, è spaventosamente più difficile. Noi siamo in grado di riconoscere una mela già dopo averla vista una volta; ad un computer servono migliaia di esempi per farcela. Noi siamo in grado di afferrare ciò che rende “mela” una mela già al primo colpo; un computer ha bisogno di algoritmi appositi. Vediamone alcuni.
PRENDERE IL TORO PER LE CORN(ER)
(Scusate il terribile gioco di parole…)
Un modo ovvio per riconoscere un oggetto consiste nel ricordarsi, tra i vari dettagli del “come è fatto”, insomma la sua forma. Forma significa bordi, e i bordi sappiamo come estrarli. Tuttavia, i bordi non sono una feature adatta per un computer. Dovete considerare una cosa: noi esaminiamo il mondo nella sua interezza; noi guardiamo una scena, un’immagine, e la analizziamo tutta insieme. Un computer no. Un computer, presa un’immagine, ne esamina un pezzo per volta, da sinistra a destra e dall’alto verso il basso. È inevitabile; fare diversamente significherebbe un carico computazionale troppo elevato. Ma esaminare una scena un pezzo per volta significa anche che in un pezzo potrebbe capitare solo una parte del bordo della mela, magari un pezzo di arco, e quel pezzo di arco potrebbe essere confuso per un altro pezzo di arco da un’altra parte della scena e che viene ad esempio da un mappamondo.
Questo non accade, però, per gli angoli. Con un angolo non c’è confusione: in un pezzetto di immagine, l’angolo entrerà tutto. Inoltre, se cambiamo punto di vista, l’angolo resta lì, quindi è anche più probabile che riusciamo a rilevarlo in scene diverse da quella corrente.
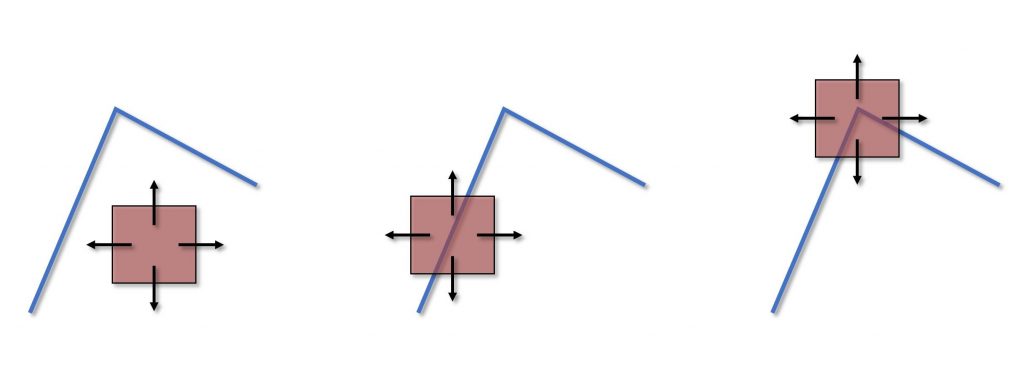
Figura 2: Come rilevare un angolo
Come rilevare un bordo lo sappiamo, ma come si rileva un angolo? Osservate la Figura 2, e immaginate che il rettangolino rosa sia una finestra che di volta in volta ritaglia un pezzettino di immagine da elaborare. Se muoviamo la finestra mentre si trova sopra ad un’area “piatta” dell’immagine, un’area di colore uniforme, ad esempio, il suo contenuto non cambierà granché. Se la finestra si trovasse sopra ad un bordo verticale, e la muovessimo a destra e a sinistra, avremmo una variazione potenzialmente elevata (dipende ovviamente da quanto è marcato il bordo), mentre se la muovessimo verso l’alto o verso il basso avremmo una variazione molto più contenuta. Se, invece, la finestra si trovasse sopra ad un angolo, in qualsiasi direzione la muoviamo otterremmo una variazione elevata.
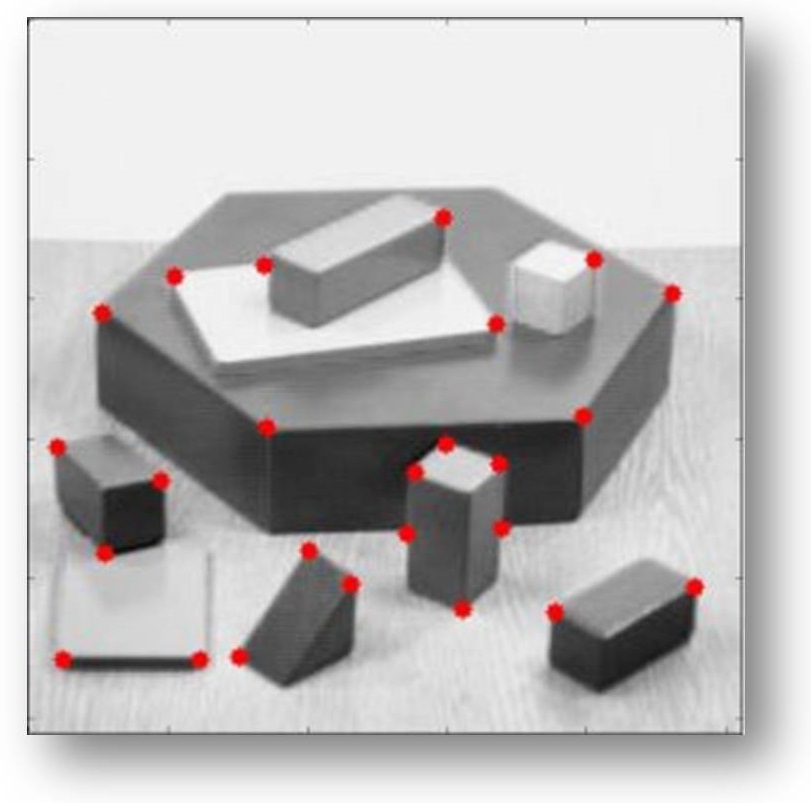
Figura 3: Harris corner detector in OpenCV
Questo è il principio alla base dell’Harris corner detector (che prende il nome da colui che lo ha inventato). Partendo da questa osservazione, Harris ha fatto un pò di calcoli (non terrificanti, ma non vi ammorberemo) per estrarre un numero che valuti la bontà di quello che c’è dentro la finestra, di quanto angoloso sia l’angolo, per così dire. Non c’è bisogno di scendere troppo nel dettaglio in quanto OpenCV ha al suo interno anche l’implementazione di questo algoritmo che, come si vede dalla Figura 3, funziona.
Gli angoli sono una feature sicuramente distintiva di molti oggetti, sono invarianti per rotazione (nel senso che se osservassimo un televisore da un angolo diverso, comunque potremmo identificarne facilmente i quattro angoli), ma non sono invarianti per scala. Potreste farmi notare che un angolo sempre angolo rimane se il televisore viene visto da lontano, ma ricordate sempre che un computer non osserva una scena nella sua interezza, ma un pezzo per volta, attraverso il rettangolino rosa che scorre su di essa.
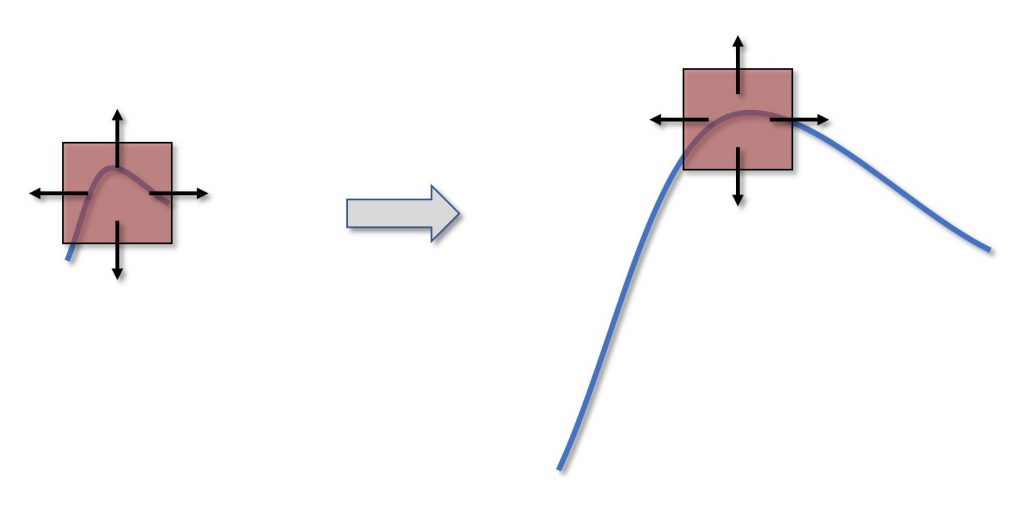
Figura 4: Gli angoli non sono invarianti per scala
Considerate la situazione nella Figura 4. Qui abbiamo un angolo abbastanza dolce che, se la scala è abbastanza piccola, entra interamente nella finestra e può essere identificato correttamente. Se però ingrandissimo la scala, se guardassimo il televisore da più vicino, l’angolo non entrerebbe più tutto in una finestra solamente, e non è detto che l’algoritmo sia in grado di identificarlo correttamente. Questo rappresenta un grosso limite per questo algoritmo, perlomeno se l’applicazione che si ha in mente è quella di feature matching, ossia del ritrovare una feature presa da una scena in un’altra.
L’IMPORTANZA DI ESSERE INVARIANTE
Se, dunque, bordi ed angoli sono una feature affidabile fino ad un certo punto, perché non consideriamo il contenuto? Perché, invece di soffermarci sulla cornice di un televisore, non prendiamo lo schermo? [...]
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 3050 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Batterie di nuova generazione: cosa bolle in pentola?
Material handling nella fabbrica intelligente: sensors everywhere
Progetto di un Chatbot IA con NLP e Python – Puntata 2
#5 Development board per applicazioni IoT
Dai LED wearables al mantello dell’invisibilità
