
Il riconoscimento vocale è l’interfaccia utente del futuro e la tecnologia è oramai pronta per affrontare applicazioni industriali e di home automation. In questo articolo verrà descritto l’uso del tool QT2SI, un software per la creazione di comandi vocali speaker-independent. Il tool Quick T2SITM di Sensory Inc. è specificamente disegnato per supportare il motore T2SITM (Text-to-Speaker-Independent), il quale fa riferimento alla libreria firmware proprietaria FluentChipTM. T2SI è un compatto riconoscitore vocale su base fonemica, operante in tecnologia speaker-independent, in grado di girare sugli speech-processor di tipo mixed-signal della famiglia RSC-4x. Il tool Quick T2SI permette di integrare, in modo molto semplice, il riconoscimento vocale nelle proprie applicazioni circuitali. Tramite una comoda interfaccia grafica, l’utilizzatore può fornire una lista di comandi vocali, anche in Italiano, che vengono in seguito compilati e linkati alla propria applicazione.
Introduzione al riconoscimento vocale
In generale, un’applicazione basata sul riconoscimento vocale consiste tipicamente in un’interazione uomo-macchina sulla base di determinati comandi verbali. Questi comandi, che possono essere singole parole o anche frasi, costituiscono il Vocabolario dell’applicazione. Ad essi ci si riferisce come le “frasi di comando” (command phases) e devono essere immesse nel progetto e definite come set di comandi che il sistema si aspetta dall’utente. Dal punto di vista operativo, tali frasi possono anche essere precedute da una frase scatenante, detta trigger phrase. Se si lavora in questa modalità, l’applicazione si pone in continuo ascolto fino a che la trigger phrase viene riconosciuta, dopodichè l’utilizzatore può fornire la vera e propria command phase. Entro il tool Quick T2SI la trigger phrase e il vocabolario dei comandi, che possono essere anche multipli, si immettono come set separati, ma sono organizzati entro un unico progetto.
Modi di funzionamento
Esistono differenti approcci con cui un’applicazione può essere strutturata. In generale, è comodo fare in modo che sia il sistema a richiedere all’utente di fornire un comando. Nei casi più semplici questo si realizza per mezzo dell’accensione di un led o con un semplice “beep”. Se invece il sistema è in grado a sua volta di “parlare”, ovvero di produrre sintesi vocale (come appunto è il caso dei processori RSC-4x), l’interazione uomo-macchina diventa un vero e proprio dialogo a domanda-risposta. A seconda delle risposte il sistema effettua opportune azioni. L’approccio citato viene definito prompted recognition. Se non viene data risposta in una certa finestra temporale, il sistema può assumere o che la risposta sia andata perduta o che essa non vi sia stata; di conseguenza, può intraprendere opportune azioni correttive, come ripetere la domanda, eccetera. Un secondo approccio prevede che sia l’utente ad avere l’iniziativa, nel senso che l’applicazione deve reagire solo quando l’utente interazione viene definita continuous listening. I rumori di fondo possono, in questo caso, produrre dei falsi riconoscimenti. In entrambi gli approcci, una volta che il parlato è stato identificato, l’applicazione deve decidere quando la risposta dell’utente è terminata, il che viene definito end-point detection. Di solito, è sufficiente aspettare un periodo di silenzio sufficientemente lungo, oppure sospendere il riconoscimento quando il programma è confidente di aver identificato una delle command phrases del vocabolario, ciò che viene definito early stop end-pointing. Vi è infine un’altra modalità, molto interessante, che consiste nel riconoscere una frase frammista ad altre parole, estranee al vocabolario. Questa tecnica richiede una certa mole di elaborazione, ma con i processori RSC-4x è possibile ed è detta word spotting. Il tool Quick T2SI permette di costruire due tipologie di riconoscitori; il primo riconoscitore è di tipo word-spotting-prompted, cioè tale che il riconoscimento è di tipo word-spotting e dev’essere preceduto da una richiesta. Il secondo può gestire un burst di segnale audio seguito da una pausa di 300ms di silenzio. La risposta-utente si assume ovviamente che appartenga al set del vocabolario predefinito e può anche essere inframmezzata da parole non del vocabolario. Il secondo tipo di riconoscitore è di tipo continuous listening con early stop end-pointing.
UTILIZZO DEL TOOL
Quick T2SI si può richiamare per mezzo dell’icona sul desktop creata in fase di installazione o tramite il menu Start di Windows. La prima volta che si utilizza occorre fornire il codice della licenza di attivazione nella opportuna entry box (figura 1), dopodichè si sceglie l’opzione ‘Validate’ per la conferma e la registrazione della chiave immessa.

Figura 1. Inserimento della chiave per la licenza
Apertura di un progetto
La prima operazione da fare è creare un nuovo progetto o aprirne uno già esistente (figura 2).
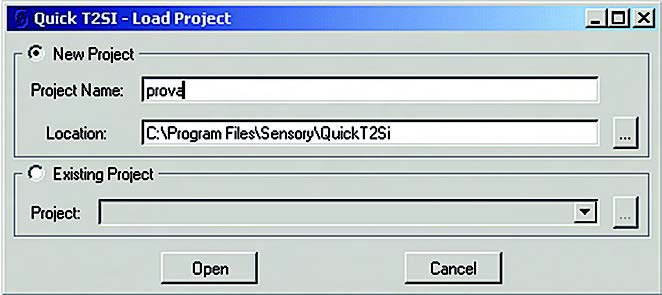
Figura 2. Apertura o creazione di un progetto
Il menù di tipo pull-down consente anche di accedere alla lista dei progetti più recenti a cui si è lavorato. All’interno della directory ove si situa il progetto è collocato il project file, con estensione “.rsc” che ne contiene i parametri descrittivi. All’interno dell’applicativo è possibile accedere all’help sia a partire dal menù principale che mediante opportuni iperlinks di tipo context-sensitive che fanno capo a specifiche funzioni.
Definizione del Vocabolario
Una volta che il progetto sia stato creato, o caricato, è possibile accedere a differenti schermate cliccando sulle tab che appaiono direttamente al di sotto del menù principale. Nella figura 3 è evidenziata la form “Vocabulary”, dove vengono inserite le command phrases che costituiscono il set di comandi che l’applicazione deve riconoscere. Il primo campo è dedicato alla trigger phrase; può essere compilato o meno, a seconda dell’impiego.
La trigger phrase
La trigger phrase, detta anche wake-up phrase, permette all’utente di richiamare l’attenzione dell’applicazione prima di inviare il comando vocale vero e proprio. L’applicazione, infatti, per la maggior parte del tempo si trova in uno stato definibile di “riposo vigile” (sleep), in continuo ascolto della trigger phrase. Solo quando questa viene correttamente riconosciuta l’applicazione si sblocca, ponendosi nella condizione di riconoscere una delle command phrases del vocabolario. Nell’esempio di figura 3 è stata inserita la frase “computer wake up“.
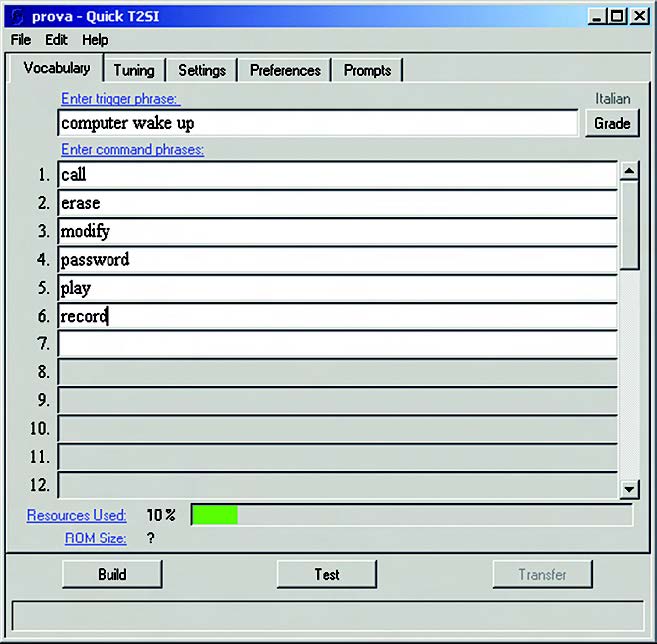
Figura 3. Definizione del Vocabolario
Da notare che Quick T2SI consente di inserire la trigger phrase semplicemente digitandola da tastiera, cosa che a prima vista può sembrare ovvia, ma in realtà non è affatto banale. Infatti, questo comporta la capacità di identificare il testo, scomporlo nei fonemi elementari e riferirlo a un database contenente tutte le espressioni verbali di una determinata lingua (Inglese, Francese, Italiano, eccetera).
Le command phrase
Le command phrase tipicamente si utilizzano nel modo prompted recognition, come alternativa al continuous listening. Sono organizzate come una lista di parole singole o frasi. Il riconoscitore, quando richiamato all’interno di un programma applicativo, effettua il match tra ciò che viene pronunciato e le command phrase contenute nella lista e ritorna al programma chiamante la command phrase che più vi assomiglia. Se nessun riscontro positivo è stato trovato, ritorna il parametro NOTA, che ha il significato di none-of-the-above. Se infine nessun comando verbale viene rilevato entro un predefinito lasso di tempo, la funzione di riconoscimento termina per scadenza del time-out. Per specificare le command phrase, come per la trigger word è sufficiente digitarle da tastiera nei vari campi numerati. Nell’esempio sono state inserite la parole “call, erase, modify, password, play, record“.
Risorse utilizzate
Chiaramente il vocabolario di comandi non può essere illimitato, ma può raggiungere una certa taglia determinata dalla capacità di memoria FLASH o ROM a disposizione. Per aiutare il progettista a valutare l’occupazione di memoria, l’applicativo effettua una stima delle risorse impiegate per quel vocabolario, che viene riportata nella riga sul fondo della pagina. Un’applicazione può avere anche più vocabolari. L’indicazione suddetta è relativa al singolo vocabolario.
Test del vocabolario
Una volta che il vocabolario è stato definito con le desiderate command phrase e l’eventuale trigger phrase, Quick T2SI mette a disposizione la possibilità di effettuarne un test direttamente su PC, che deve disporre di scheda audio, microfono e cuffia. La procedura di test si può ripetere più volte, per verificare che ciascuna parola / frase venga riconosciuta in modo affidabile. Per fare questo, occorre cliccare sul tasto “Test” sul fondo della finestra (subito dopo il tasto cambia in “Stop”, come in figura 4).
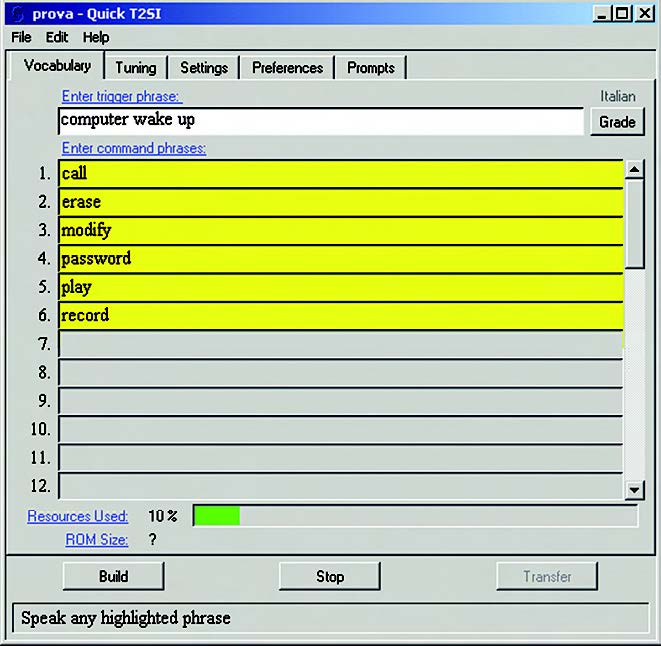
Figura 4. Inizio della fase di test del vocabolario dei comandi
L’inizio del test si manifesta con un segnale acustico mentre la trigger word (se esiste) viene evidenziata su sfondo giallo. L’operatore può quindi pronunciare la trigger word. Se riconosciuta con successo, il rispettivo campo diventa a sfondo bianco e un successivo “beep” annuncia il passaggio alla fase successiva, in cui tutti i campi delle command phrase diventano gialli. A questo punto l’operatore pronuncia una command phrase e, se il riconoscimento avviene con successo, il campo di quella command phrase si muta in verde (figura 5).
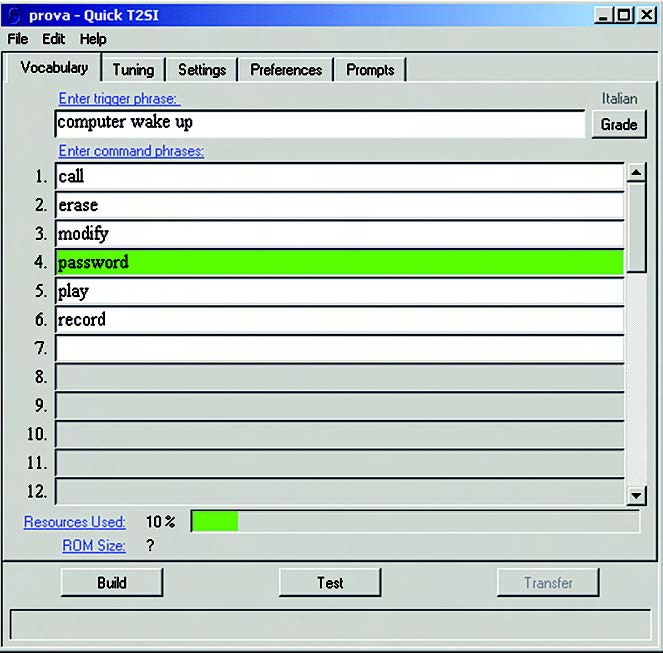
Figura 5. Esito del riconoscimento di una command phrase
In caso contrario, la procedura termina con il messaggio “Out of Vocabulary”. Vi possono essere alcune frasi particolarmente difficili da riconoscere. In tali casi i motivi possono essere di diversa natura, ad esempio una pronuncia non standard oppure la presenza di più frasi che hanno una pronuncia simile e quindi possono essere confuse tra loro o, infine, un livello del segnale audio troppo debole. La prima situazione si affronta con una metodologia detta di tuning, che vedremo in seguito; questa permette di modificare lievemente le pronunce delle varie frasi, fino ad ottenere il miglior risultato per l’applicazione. Riguardo le ambiguità dovute a parole/frasi con pronuncia simile, una buona strategia consiste nel scegliere già dall’inizio un set di vocaboli abbastanza diversi tra loro. Infine, è bene fare in modo che il segnale dal microfono sia di livello né troppo basso né tale da mandare in saturazione l’ingresso della scheda audio.
Figura 6. Download verso la demo-board
Compilazione del vocabolario
Prima di essere trasferito sulla demo-board per RSC-4x, il vocabolario deve essere sottoposto a compilazione per essere convertito in formato binario. Per dare inizio alla compilazione occorre cliccare sul tasto “Build”. Come requisito fondamentale, è necessario avere previamente installato il package Phyton-SE, comprendente Assemblatore e Linker, nonché la già citata libreria FluentChip di Sensory. Al termine del procedimento, entro la cartella di progetto vengono generati diversi files, di cui i principali sono i seguenti:
- trig_rscApp_<project name>.hInclude-file per la trigger phrase, da utilizzare per applicazioni in linguaggio C
- trig_rscApp_<project name>.inc
Include-file per la trigger phrase, da utilizzare per applicazioni in linguaggio Assembler - trig_rscgram_<project name>.mcoGrammatica compilata (file oggetto) per la trigger phrase
- comm_rscApp_<project name>.hInclude-file per le command phrase, da utilizzare per applicazioni in linguaggio C
- comm_rscApp_<project name>.incInclude-file per le command phrase, da utilizzare per applicazioni in linguaggio Assembler
- comm_rscgram_<project name>.mco
Grammatica compilata (file oggetto) per le command phrase - rscnet_<project name> .mcoModello Acustico compilato.
- t2si.binFile eseguibile da scaricare sulla demo-board (in formato binario)
Le frasi di trigger e command vengono compilate in files oggetti separati, che vanno poi linkati con l’applicazione insieme al modello acustico. Con il termine modello acustico si intende il database caratteristico del tipo di voce (ad esempio adulto, bambino, eccetera). L’argomento verrà trattato nel seguito.
Test del Riconoscitore sulla demo-board hardware
Nel paragrafo precedente abbiamo visto che il processo di Build genera un certo numero di files. Ci si può chiedere, a questo punto, quale sia il loro significato (in prima analisi potrebbe non essere evidente). Consideriamo dapprima il file eseguibile t2si.bin; si tratta di un’applicazione completa, costruita ad hoc dal tool stesso in modo trasparente all’utilizzatore, che permette di testare il Vocabolario appena creato, in maniera molto simile a quanto già fatto per mezzo della funzionalità “Test” propria dell’ambiente software, ma questa volta sulla demo-board. Naturalmente questo file eseguibile dovrà avere un sorgente associato, per la precisione un file denominato t2si.mca descritto in linguaggio Assembler. Il tool lo genera, ma lo cancella alla fine del procedimento. L’eseguibile può essere quindi scaricato sulla demo-board equipaggiata con processore RSC-4x, che va collegata al PC tramite linea seriale. Il trasferimento viene attivato con il tasto “Transfer”. Dopo aver verificato la presenza dell’harware, il tool provvede ad informare l’utilizzatore ad attivare lo switch sulla demo-board denominato “Program”. Al termine del trasferimento, l’applicazione demo è pronta. A questo punto è sufficiente premere il pulsante di Reset sulla piastra per dare inizio al test. Il programma si manifesta con dei prompt vocali. All’inizio, ad esempio, richiede di pronunciare la trigger word, aspettare un “beep” e pronunciare una command word :
“Say the trigger word” and wait for a beep, then say a command word”
In seguito, una volta riconosciuta una command word, comunicherà di quale si tratta in base al suo numero d’ordine nella lista del Vocabolario :
“You said word <n>”
Come piattaforma di sviluppo hardware, Sensory fornisce per esempio il Toolkit (figura 7) comprensivo della demo-board con processore RSC-4x a bordo.

Figura 7. Demo-board fornita nel Toolkit di valutazione
Per quanto riguarda gli altri files prodotti da Quick T2SI con la fase Build, essi consistono in tutto il necessario per produrre una propria applicazione; quindi, files di tipo “include” da inserire a livello di intestazione nel sorgente (sia Assembler che C) e files oggetti ad uso del Linker. Questi ultimi sono la traduzione compilata delle grammatiche di trigger e command. In questo articolo, per ragioni di spazio, non ci occupiamo di come costruire un’applicazione, perchè il nostro scopo è principalmente di descrivere le caratteristiche del tool.
MIGLIORARE LE PRESTAZIONI: IL TUNING
Come già detto, il tool Quick T2SI consente di raffinare la pronuncia di quelle parole o frasi che risultano particolarmente critiche, operazione detta di Fine Tuning. Per accedere alla relativa interfaccia grafica occorre cliccare sulla tab “Tuning” (vedere figura 8a).
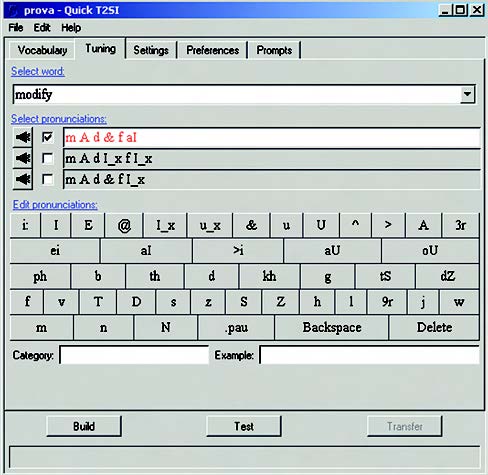
Figura 8A. Raffinamento (tuning) della pronuncia
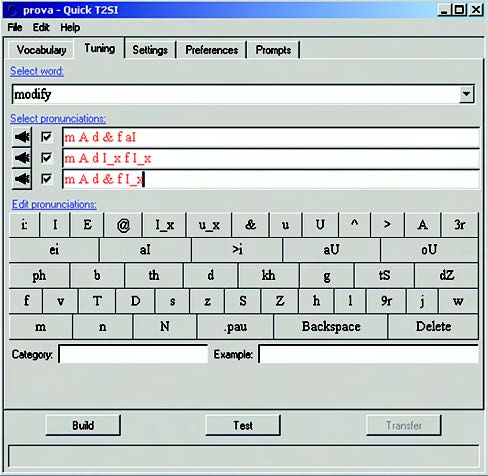
Figura 8B. Selezione delle diverse espressioni
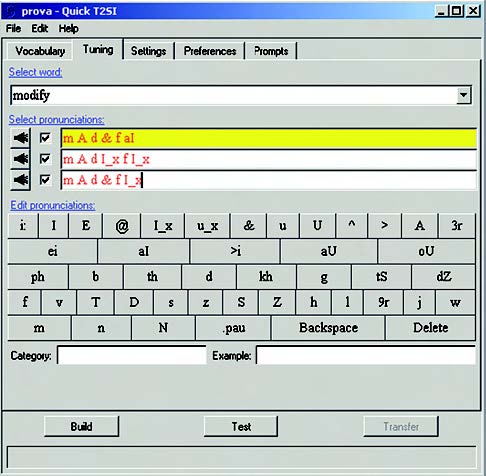
Figura 8C. Indicazione della pronuncia ottima
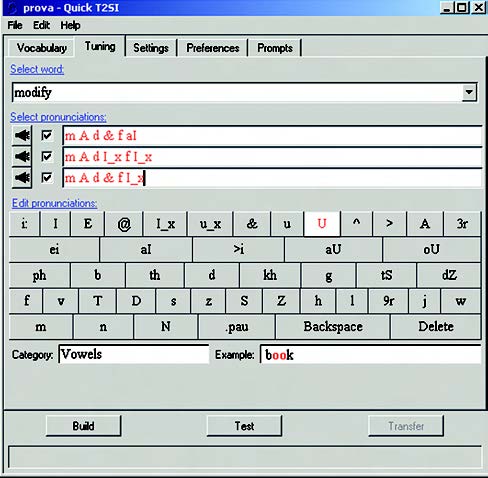
Figura 8D. Utilizzo della tastierina per l’editing
Si procede nel seguente modo: inizialmente, dal menù a tendina “Select word” occorre selezionare la parola/frase da raffinare, a scelta fra trigger e command phrase. Sia questa, ad esempio, “modify”. La pagina presenta tre differenti pronunce di default per questa parola. È possibile ascoltarle, una per una, selezionando la relativa box e cliccando sull’icona a sinistra raffigurante un altoparlante. Il sintetizzatore vocale integrato nel tool pronuncia la parola evidenziata in base ai fonemi di cui è composta. Per mezzo della tastierina sottostante, l’utilizzatore può quindi modificare la pronuncia editando i fonemi, fino ad arrivare all’ottimizzazione della pronuncia. Per facilitare l’operazione, è possibile anche effettuare dei test di pronuncia (clic sul tasto “Test”)
Modifica dei parametri di riconoscimento
Per modificare i vari parametri e i settaggi del tool, occorre cliccare sulla tab “Settings”, al che si presenta la form di interfaccia riportata in figura 9.
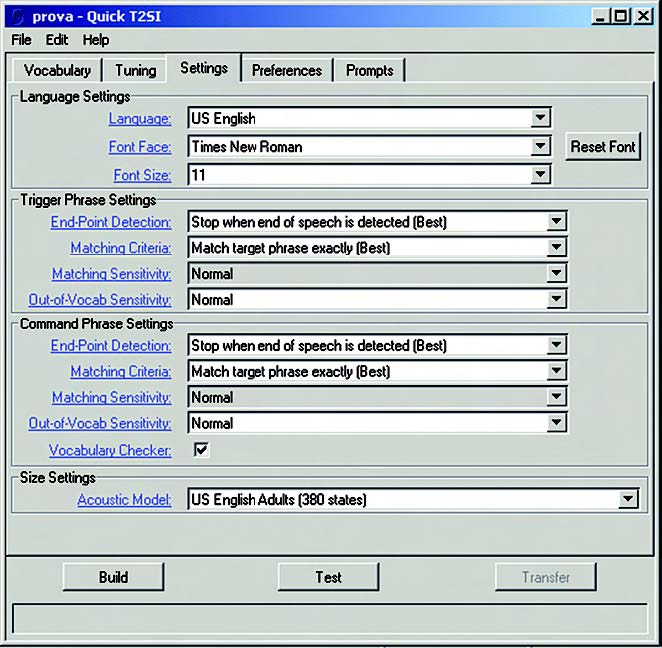
Figura 9. Parametri e settaggi del tool di riconoscimento
I settaggi sono duplicati per la trigger phrase e per le command phrase, così da avere la massima libertà nell’impostazione. Infatti, in certi casi può essere utile rendere i settaggi della trigger phrase più stringenti di quelli delle command phrase, in modo da ridurre le “false partenze”.
Lingue supportate
Le lingue ed eventuali dialetti gestiti da QT2SI sono elencati nel menù a tendina “Language”. Il set si può estendere, a condizione di installare il package opportuno e attivare la relativa licenza. Dopo l’installazione di un nuovo package, per renderlo operativo occorre rilanciare il tool. Ad oggi, le lingue gestite sono le seguenti:
Inglese (Usa e UK), Spagnolo (Spagna e Latino-America), Italiano, Tedesco, Giapponese, Cinese (Mandarino), Coreano. Francese e Portoghese sono in corso di sviluppo.
RILEVAZIONE DELL’”END-POINT”
Come già accennato, il Riconoscitore ha bisogno di determinare in quale istante l’utilizzatore termina di parlare, in modo da poter restituire il risultato del riconoscimento al programma chiamante. Questa funzione è detta end-point detection. Nella figura 10 sono visibili i campi relativi al settaggio di questa funzione.
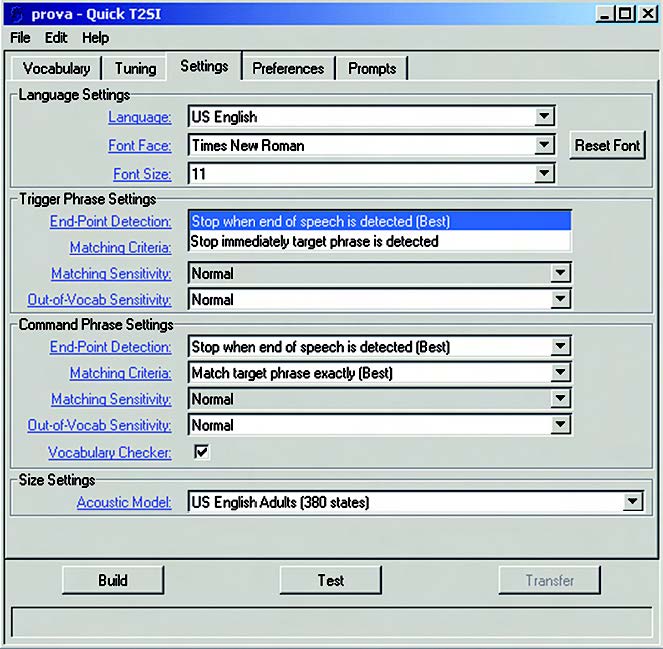
Figura 10. Setting dell’end point detection
Il metodo più affidabile consiste nell’aspettare un’adeguata pausa di silenzio (300 ms). La seconda opzione comporta di fermare il processo non appena il Riconoscitore è confidente di avere individuato la frase entro il vocabolario; questa funzione è detta early-stop end pointing.
CRITERI DI “MATCH” E DI SENSIBILITÀ
Un altro settaggio importante è quello del criterio per stabilire l’identificazione (match) del comando vocale (figura 11).
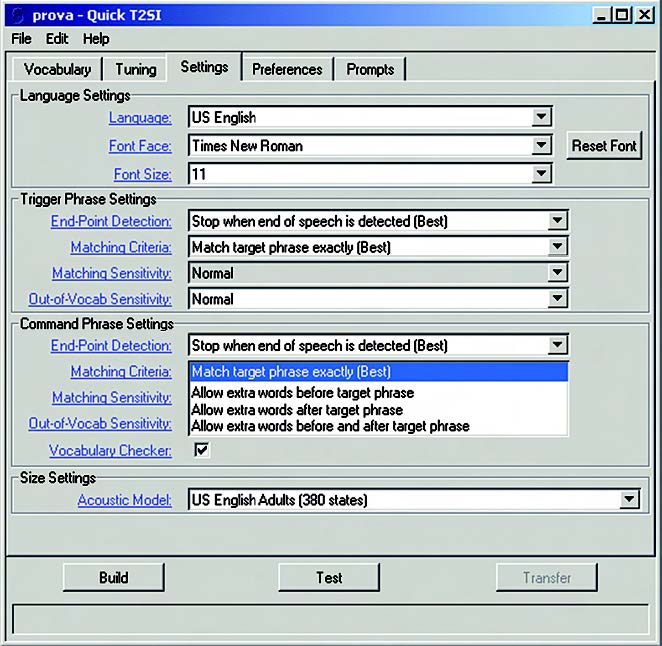
Figura 11. Setting del grado di confidenza del match
Il Riconoscitore supporta diverse strategie per catturare la frase target. In generale, si tratta di varie implementazioni della modalità word spotting. Nel senso che si può dare per buona la frase target quando viene pronunciata da sola (match exactly), oppure quando si riesce ad estrarla da un contesto in cui possono essere presenti altre parole-extra prima o dopo di essa. La prima implementazione è quella che dà i migliori risultati. Il meccanismo di riconoscimento assegna ad ogni acquisizione un certo “punteggio” (score). Agendo sul parametro definito Out of Vocab. Sensitivity è possibile modificare la sensibilità del modello di word spotting nei confronti delle frasi che sono al di fuori del vocabolario. Ponendo questo parametro a “reject fewer” si fa in modo che vengano accettate facilmente frasi al di fuori del vocabolario, mentre “reject most” riduce la reattività alle frasi estranee. Il valore di default è “Normal”. Questi settaggi vanno modificati con molta attenzione e salvati solo dopo aver verificato il funzionamento del riconoscitore nell’ambiente reale.
Selezione del Modello Acustico
La precisione del riconoscimento migliora quanto piu accurato è il modello che si impiega. Si osserva sperimentalmente che vi sono gruppi di persone che possiedono caratteristiche vocali piuttosto marcate, come ad esempio i bambini più piccoli, i quali pronunciano alcune parole con una certa imprecisione. Per questo motivo ciascun package linguistico, oltre ad essere specifico per una certa popolazione target, è composto a sua volta da un set di Modelli Acustici. Questi sono database vocali caratteristici delle varie fasce di età (bambini, adulti, eccetera). In figura 12 viene mostrato come selezionare un particolare Modello Acustico.
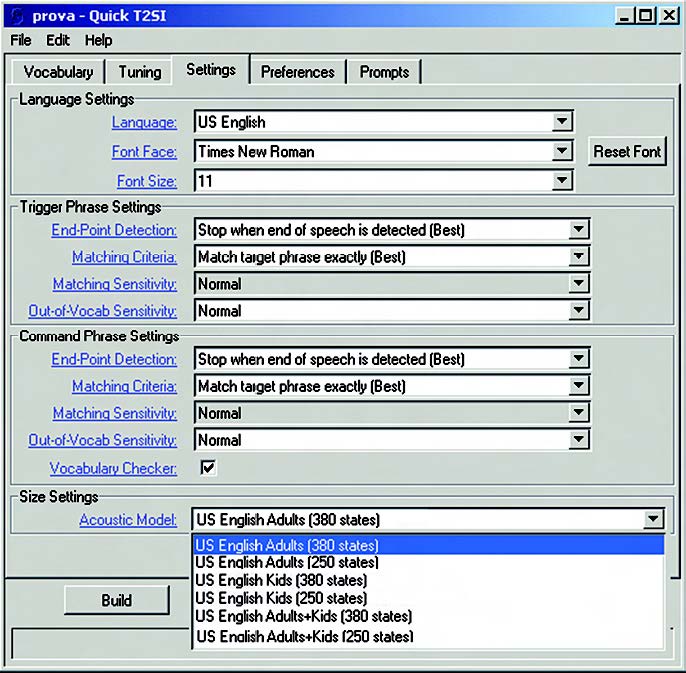
Figura 12. Selezione del Modello Acustico
Un altro fattore di cui tenere conto è costituito dal numero di “stati” interni del modello. Un modello con molti stati fornisce una migliore performance, ma ha l’inconveniente di occupare più memoria. La strategia migliore consiste nell’impiegare il modello più ampio possibile compatibilmente con le risorse a disposizione. A parità di risorse, un modello di taglia inferiore consente di avere un vocabolario più esteso.
Configurazione delle “User Preferences"
La figura 13 riporta la pagina per il setting dei parametri preferenziali di utente.
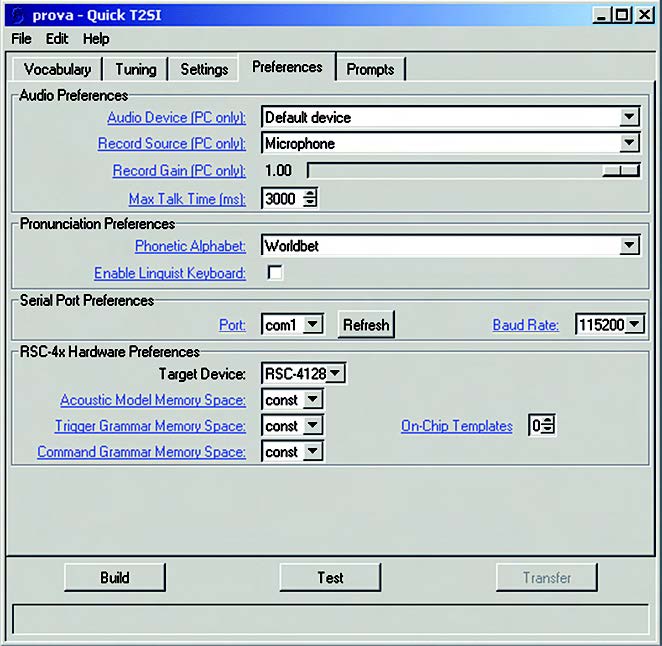
Figura 13. Setting delle User Preferences
In sostanza, questi parametri riguardano le caratteristiche dell’audio; alcune sono specifiche del PC, altre si riferiscono alla piattaforma target RSC-4x. Le caratteristiche del PC sono relative al tipo di scheda audio, alla sorgente di registrazione (microfono, line-input, eccetera), all’impostazione del guadagno. Riguardo il guadagno di registrazione, è buona norma predisporlo a un valore intermedio, senza eccedere, per evitare fenomeni di saturazione che potrebbero falsare i risultati. Un altro parametro utile è il massimo periodo di registrazione (Maximum Talk Time). Questo settaggio si applica soltanto alle frasi di comando (non di trigger) e si misura in millisecondi. Se si supera questo valore, il riconoscitore restituisce il messaggio di errore “talked too long”.
Configurazione dei parametri della pronuncia
Questa sezione è relativa alla scelta dell’Alfabeto Fonetico. Che cosa si intende con questo termine? In ambiente tecnico si utilizzano diversi alfabeti fonetici, comprese alcune varianti di alfabeti. Un tentativo recente di standardizzazione è costituito dal modello VoiceXML, che si riferisce all’Alfabeto Fonetico Internazionale IPA. Lo standard IPA è piuttosto complesso e utilizza un set di caratteri speciali. Questo fatto ha incoraggiato la creazione di altri alfabeti, descritti in maniena più semplice. Ne è nata una rappresentazione in formato ASCII adatta a descrivere i fonemi di più lingue, che è stata adottata da Worldbet e X-Sampa. Di questi, Worldbet è senz’altro l’alfabeto più completo e più simile all’IPA, semplice da imparare e gestire. Sensory suggerisce di utilizzare Worldbet, che è la scelta di default del tool QT2SI. La tastierina di interfaccia fonetica permette di gestire sia l’uno che l’altro alfabeto. La figura 14 mostra l’aspetto della tastierina quando si seleziona IPA.
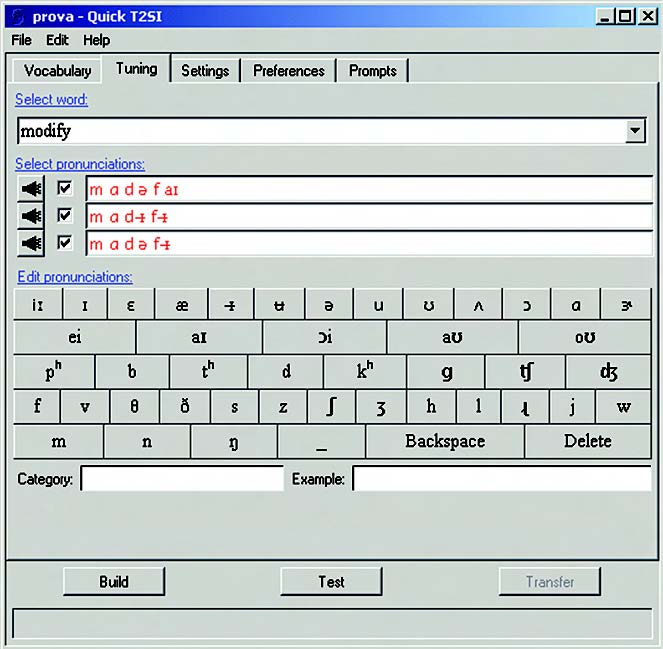
Figura 14. La tastierina fonetica nel caso di Alfabeto fonetico IPA
Ancora a proposito della tastierina fonetica, occorre ricordare che è configurabile in due modi, denominati standard e linguist, per mezzo della checkbox denominata “Enable Linguist Keyboard”. Il modo standard (quello di default) consente di avere un set di fonemi ridotto. Il modo linguist non è raccomandabile per chi non ha pratica del tool.
Settaggio dei parametri preferenziali della Grammatica
Esiston alcuni settaggi che si riferiscono alle modalità con cui la Grammatica (intendendo con questo termine l’insieme dei comandi creati per l’applicazione) viene compilata ed eseguita. Questi settaggi hanno influenza sia sulla taglia che sulla velocità di esecuzione dell’applicazione. I parametri in questione riguardano la selezione dello spazio di memoria per la trigger phrase e per le command phrase. Per i processori RSC-4x i dati per il programma applicativo possono essere allocati in differenti aree di memoria, che sono le seguenti:
- CONST: è la porzione di ampiezza 128Kbyte situata più “in basso” nell’ambito dello spazio di indirizzamento totale (1Mbyte) e viene condivisa con il codice eseguibile. Il Linker genera un codice binario da allocare nello spazio di tipo code/const. Può risiedere nella ROM interna o in una esterna.
- DATA : è lo spazio di indirizzamento da 1MByte esterno all’RSC-4x. Il Linker crea un codice binario specifico per questo spazio di memoria.
- FDATA, NDATA : sono aree di memoria simili alla DATA; possono essere utili per certe applicazioni scritte in C. Non sono utilizzate per le applicazioni scritte in Assembly.
Configurazione della porta seriale
Il programma di esempio che viene generato dal processo di Build è fatto per essere eseguito su una demo-board standard con processore RSC-4x a bordo, come quella raffigurata in figura 7a. È necessario quindi trasferire il codice binario via RS232. Il tool dev’essere configurato per comunicare con la porta seriale collegata alla scheda di valutazione. Nella sezione “Serial Port Preferences” si può scegliere tra com1 e com2. Occorre settare la velocità di comunicazione alla massima consentita dal computer e dalla lunghezza del cavo, per esempio 115200 baud.
PARAMETRI PREFERENZIALI PER L’HARDWARE RSC-4X
ROM a “Zero Wait State”
La memoria ROM normalmente presente sulle schede di valutazione standard per chip RSC-4x richiede un accesso da un wait state. Tuttavia, il tool permette anche di utilizzare memorie con accesso a zero wait state. Questo permette al codice una velocità di esecuzione di circa il 50% superiore, riducendo nel contempo i ritardi di latenza. L’opzione “Zero Wait State ROM” richiede che la memoria abbia un tempo di accesso di 70 nsec al massimo. Per quanto riguarda la ROM interna dell’RSC-4x, per la maggior parte i chip di questa famiglia sono in grado di lavorare a Zero Wait States (conviene comunque consultare i datasheet).
DEFINIZIONE DEI “PROMPTS” DI USCITA
Il pannello cosiddetto dei “Prompts” (evidenziato in figura 19) permette di inserire nel progetto delle particolari parole o frasi, registrate con la voce dell’utilizzatore, che il Riconoscitore potrà emettere durante l’esecuzione. A questi ci si riferisce come “prompts di uscita”. In questo modo il programma di riconoscimento, ogniqualvolta identifica una determinata frase, ne dà conferma ripetendola. Ovviamente questo comporta la necessità di creare tanti files (in formato wave) quante sono le frasi del Vocabolario. In questa sezione, cliccando sui tasti Record e Play, è possibile effettuare rispettivamente la registrazione con salvataggio su file e il riascolto dei pattern vocali, così da generare e verificare tutti i prompt audio che verranno inseriti nel progetto. Il tasto File permette invece di caricare un file audio già creato esternamente al tool. Inoltre, una speciale entry indicata <application prompt> permette di specificare il prompt principale, quello cioè che il tool pronuncia all’inizio del test. Se si lascia il campo vuoto, il sistema utilizza un prompt di default.
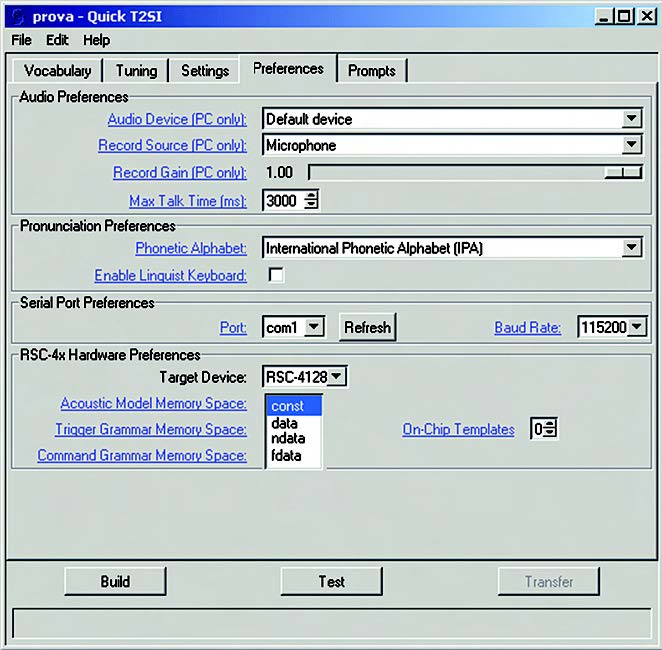
Figura 15. Parametri preferenziali della Grammatica
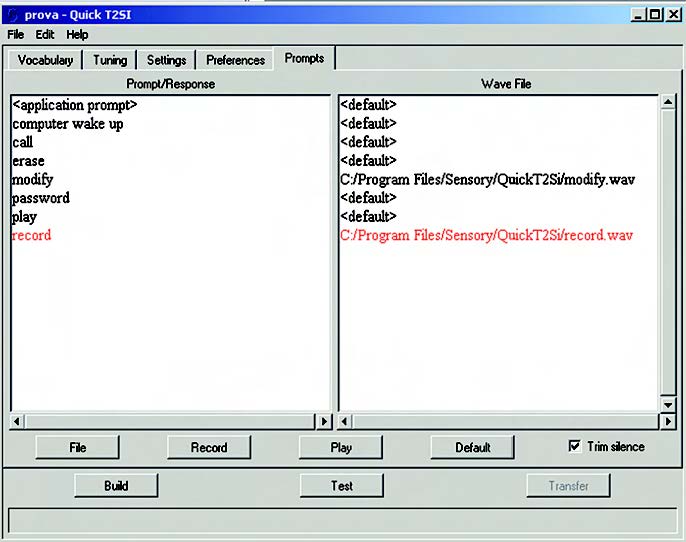
Figura 16. Pannello dei prompts di uscita


Il riconoscimento vocale è senza dubbio una tecnologia di interfaccia che ha avuto un buon successo e lo continuerà ad avere soprattutto nel settore automotive, ma anche in molti altri settori delle telecomunicazioni.
La sensory ha dismesso la produzione del microcontrollore RSC-4128 e di conseguenza non è più possibile scaricare il software né acquistare la licenza in quanto si è dedicata a sviluppare un’applicazione per processori arm cortex.
Qualcuno per caso ha questo vecchio software nella versione completa?