
Le applicazioni orientate al mondo embedded hanno la necessità di utilizzare sistemi di protezione? L’argomento mi sembra abbastanza interessante. Credo che qualsiasi azienda ha la necessità di proteggere il proprio lavoro, pensiamo ad alcune realtà asiatiche che nella copia hanno fatto un proprio proficuo business.
L’esigenza è particolarmente sentita: qualsiasi azienda ha la necessità di tutelare i propri investimenti da persone o società. Un sistema embedded tipicamente veicola il software per mezzo di un eseguibile, o binario, che si trova residente nella memoria del prodotto. Le azioni rivolte a comprendere il funzionamento di un codice eseguibile è un’attività che può essere definita di reverse engineering. In sostanza, l’obiettivo che ci si pone è quello di leggere il codice, mediante un’azione intrusiva, e decodificarne il funzionamento. Tipicamente il software a corredo di una qualsiasi applicazione embedded è di solito presente nella memoria di sola lettura del chip o della board. Con molta probabilità il sistema più sicuro è senza dubbio un’applicazione scritta in un SoC, System-on-Chip, magari utilizzando il linguaggio del SoC stesso: un linguaggio proprietario. Pensiamo, ad esempio, ad un’applicazione scritta in VHDL e inserita come IP in un FPGA: senza dubbio tentare di carpire il segreto di un sistema del genere è un’avventura di difficile soluzione. In questa situazione occorrerebbe monitorare i segnali per tentare di capire il funzionamento: un’impresa sicuramente improponibile. Il tentativo di decodificare il codice binario è anche chiamato processo di reverse engineering. In sostanza, il reverse engineering è una tecnica che permette, dato un dispositivo (componente elettronico, codice binario o quant’altro) di risalire al modello comportamentale dell’oggetto in esame. Una volta compreso il modello comportamentale occorre costruirne un altro partendo da quello sotto esame avente le stesse caratteristiche e funzionalità. Tecniche di questo tipo sono utilizzate nei settori più disparati. Il segmento tipico delle applicazioni delle tecniche di reverse engineering è quello militare, il tentativo è sempre lo stesso: cercare di copiare il potenziale bellico del nemico analizzando la sua tecnologia. Esistono esempi illustri, non possiamo non ricordare il missile Scud Mod A in dotazione all’esercito della Corea del Nord: il lavoro è stato condotto utilizzando tecniche di questo tipo sui missili Scud BS appartenenti alle forze armale sovietiche. Possiamo anche ricordare il bombardiere a largo raggio Tupolev Tu-4 nato dalla tecnologia delle superfortezze volanti B-29 utilizzate dall’aviazione americana nella guerra del Pacifico; infatti, diversi bombardieri di questo tipo atterrarono in Unione Sovietica e qui furono studiati e analizzati. Un altro esempio è il computer, sempre sovietico, Agata nato dalla tecnologia Apple II. Al processo di reverse engineering si applicano le tecniche di decompilazione, la figura 1 mostra le varie fasi del processo di compilazione e decompilazione.
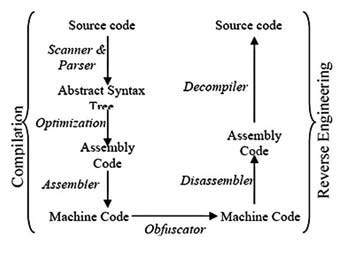
Figura 1: processo di compilazione e decompilazione.
Figura 2: dump della memoria.

Figura 3: diassemblato, sessione 1.

Figura 4: diassemblato, sezione 2.

Figura 5: iassemblato, sezione 3.
La decompilazione è il processo inverso della compilazione. Nella compilazione si traduce il codice sorgente di un programma, espresso in una notazione chiara e conosciuta, in codice oggetto. Per effetto di questo processo le istruzioni presenti nel codice devono essere tradotte in istruzioni equivalenti del processore, le funzioni presenti nelle librerie sono tradotte e tutti i commenti saranno eliminati. L’obiettivo di questo articolo è quello di mettere in evidenza alcuni accorgimenti utilizzati per proteggere il proprio lavoro. Lo strumento fondamentale utilizzato per svolgere questo lavoro è il decompilatore. La decompilazione è una tecnica familiare per chi conosce molto bene il processo di compilazione. La decompilazione è l’operazione inversa della compilazione: si crea un modello comportamentale del programma di partenza. La decompilazione è in sostanza un processo che tende ad applicare le tecniche di reverse engineering per studiare il comportamento del modello in esame, dispositivo embedded o semplice applicazione su desktop. Sicuramente occorrono anche possedere conoscenze mirate in fatto di programmazione embedded, della struttura del processore in uso e sui formati dei file e degli ambienti di lavoro. La tabella 1 mostra il formato di alcuni file tipici utilizzati per le indagini di reverse engineering, mentre le figure 6 e 7 mettono in evidenza il formato dei file ELF e EXE.
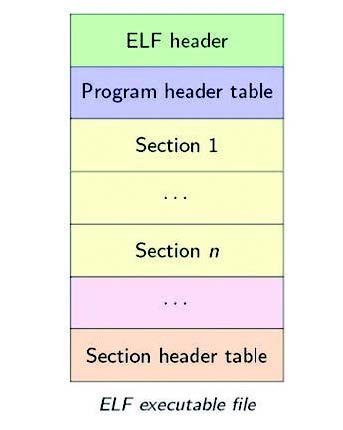
Figura 6: ELF executable file.
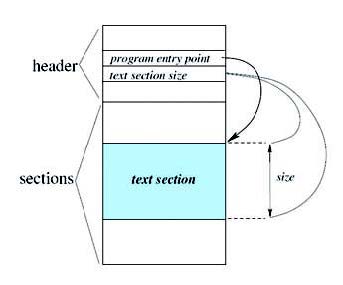
Figura 7: struttura di un file eseguibile.

Tabella 1 – Tipici file oggetto
Esistono diversi tool commerciali in grado di supportare il processo di reverse engineering. Nel segmento open-source esistono due tool che posso definire davvero interessanti per via delle funzionalità che offrono e del successo che hanno ottenuto. Parlo di Codecrawler e Rigi. Codecrawler è un tool scritto in Smalltalk utilizzato in diverse applicazioni commerciali e permette diverse viste grafiche. In alternativa Rigi offre la generazione di viste e report del codice sotto esame in maniera interattiva anche ricorrendo a script che l’utilizzatore può scrivere mediante Tcl. Non solo, con Rigi è possibile, attraverso i diversi comandi disponibili, personalizzare le astrazioni.
Metodi di protezione
In questa sezione vediamo alcune tecniche di protezione più comunemente utilizzate. Secondo il mio parere non esiste una tecnica in grado da garantire il risultato voluto, ma occorrono, probabilmente, utilizzare diverse tecniche combinate tra loro allo scopo di ottenere un buon sistema protetto. Non esiste un sistema perfettamente sicuro, ma solo un sistema che possiamo considerare sufficientemente sicuro in base allo sforzo richiesto e al risultato voluto. Fino a qualche anno fa si soleva inserire nell’eseguibile, o binario, una stringa alfanumerica: in questo modo si poteva rivendicare la proprietà esclusiva dell’opera. In realtà, un sistema di questo tipo non è propriamente un sistema che possiamo definire di protezione, ma è utilizzato solo per questioni commerciali o di diritto d’autore. Inserire una stringa nel codice binario serve solo a sprecare memoria e per un sistema embedded di piccole dimensioni è senza dubbio importante l’uso ragionato ed efficiente di questa risorsa fisica. In realtà, lo stesso obiettivo può essere raggiunto associando al binario una stringa cifrata, un checksum, mediante un algoritmo opportuno: in questo modo è possibile in ogni caso rivendicarne la proprietà esclusiva. La seconda tecnica di protezione associa un checksum al codice presente in memoria. In questo modo è impedita qualsiasi operazione di modifica del codice ricorrendo al calcolo di un checksum in fase iniziale, boot, e in maniera dinamica attraverso un opportuno CBIT, o Continuos Built In Test. Al momento del caricamento del codice nella memoria a sola lettura è necessario inserire il checksum in una locazione particolare calcolata offline. All’accensione la routine di bootstrap, dopo una verifica preliminare delle risorse hardware, deve ricalcolare il checksum e confrontarlo con quello presente in memoria. In caso di risultato discordante il programma sospende la sua esecuzione ponendosi in un ciclo iterativo infinito. Questo metodo chiaramente non offre una protezione contro i tentativi di lettura del codice per sottoporlo ad un processo di decompilazione: è, in sostanza, una protezione blanda. Infatti, questo meccanismo protegge il codice contro tentativi di modifica, voluti o meno. La parte più delicata, in questo contesto, è la scrittura del bootloader. La terza possibilità è quella di ricorrere alla crittografia delle stringhe. In un’applicazione embedded a volte è implementata un’interfaccia uomo macchina, ad esempio, utilizzata per impostare i parametri della temperatura ambientale o inserire la data o l’ora e così via. In questo contesto, le stringhe sono posizionate in una sezione costante nel nostro file binario. Questi dati sono utili in fase di decompilazione della nostra applicazione; infatti, il decompilatore ad ogni stringa cerca di associare un indirizzo di riferimento per poi ricostruire il flusso di lavoro dell’intera applicazione o ramo. Si può rendere il lavoro più difficile inserendo le stringhe in forma cifrata e trattate con proprie funzioni di gestione; ad esempio, una printf custom in grado di lavorare con diversi parametri su stringhe in memoria cifrate. Non solo, c’è chi ricorre ad un sistema operativo progettato e realizzato appositamente. Perchè una scelta simile? Di solito in un sistema operativo commerciale tutto deve essere conosciuto all’utilizzatore tanto che le informazioni sono, per forza di cose, di dominio pubblico: dalle firme presenti nel file binari alla sequenza di startup, dalle prerogative di run-time alle interazioni tra librerie e applicazioni. Un decompilatore, conoscendo la natura del sistema operativo, può tranquillamente eseguire il suo lavoro senza particolari problemi tanto da ricostruire il comportamento dell’applicazione. Di conseguenza il problema potrebbe risolversi scrivendo il proprio sistema operativo o ambiente di run-time. Sicuramente un’attività del genere non è indolore perché richiede notevoli investimenti e risorse: un aspetto da valutare attentamente. Un’altra tecnica richiede l’uso di logica addizionale in grado di fare lo scrambling delle linee di indirizzo. A questo scopo può essere utilizzato una logica, FPGA ad esempio, per pilotare diversamente le linee. In questo caso si otterrebbe un disallineamento tra le informazioni contenute nel software con quelle presenti in memoria risolte solo con la logica aggiuntiva. E se provassimo a sostituire le funzioni di libreria con una nostra implementazione appositamente realizzata? Questo è un altro aspetto da non sottovalutare ed è fortemente dipendente dalla quantità, e qualità, delle librerie da rimpiazzare. Oltre ad aggiungere un sensibile overhead alla nostra applicazione potremo pensare anche di inserire dei punti di sincronizzazione per controllare eventuali modiche alla memoria. Un altro aspetto da considerare è la possibilità di scrivere gli algoritmi che definiamo critici per la loro importanza strategica non in software ma utilizzando logica hardware, magari in VHDL. Perché non utilizzare un propria logica programmabile? La soluzione ideale rimane la definizione di un processore custom, un SoC, con propri mnemonici e sistemi di compilazione. In questo modo si vanificano tutti i tentativi di decompilazione del codice perché non si è in possesso del modello comportamentale. Certamente questa ultima soluzione non è da tutti attuabile perché richiede un notevole sforzo economico solo giustificato da un consistente ritorno economico. Altri ancora ritengono di mascherare il comportamento dell’applicazione attraverso tecniche alternative di programmazione. Ad esempio, la porzione del codice
(b * b)
è equivalente a
(b * ((13*b) (b << 4) (b << 2)) )
O ancora è possibile ricorrere all’offuscamento dei dati. Ad esempio, una variabile locale può essere convertita in globale o magari accedendo a dati di un array utilizzando meccanismi alternativi, ad esempio rimpiazzando l’indice dell’array da i a 8 * i + 3. Così, la porzione di codice:
int i = 1;
while (i < 1000) {
... A[I] ...;
i ++;
}
Può essere modificata in:
int i=11;
while (i < 8003) {
... A[(i-3)/8] ...;
i += 8;
}
Non solo, è anche possibile ricorrere all’offuscamento dei dati aggregati; in questo caso, un array bi-dimensionale può essere convertito in uno mono-dimensionale o viceversa. L’offuscamento del codice è una tecnica interessante in grado di contrastare il processo di decompilazione che acquisisce le informazioni da un processo precedente: un disassemblatore. Confondere un disassembler significa fare in modo che interpreti, ad esempio, uno o più byte di dati come l’inizio di un’istruzione allo scopo di disallineare la fase di decodifica, ma non solo, è possibile anche rendere il codice eseguibile, con gli algoritmi contenuti, non di facile e immediata lettura. In questo caso possiamo pensare di sostituire operazioni semplici con altre con una maggiore complessità di lettura non facilmente identificabile mediante una firma. A questo proposito esistono diverse tecniche che possono essere utilizzate contemporaneamente.
Tecniche di offuscamento
Con un programma si intende descrivere un comportamento ed è questa la base di un processo di decompilazione. Alcuni utilizzano tecniche particolari per ostacolare il processo di reverse engineering chiamate tecniche di offuscamento. In sostanza è modificato il codice macchina tanto da rendere il lavoro di reverse difficile da attuare o, al limite, di scoraggiarne i tentativi. Ad esempio è possibile inserire porzione di codice che non saranno mai eseguite (garbage code) o modificare l’indirizzo di ritorno di una funzione (branch function). Le tecniche si dividono in due gruppi: linear sweep con junk insertion e branch flipping e recursive traversal con junk insertion, branch functions e opaque predicates. Proviamo a esaminare qualcuno di questi costrutti. Un disassembler inizia a decodificare l’istruzione che trova al primo byte della sezione di codice e procede fino a quando non termina la sezione. Questo meccanismo è chiamato disassembly lineare o linear sweep. Un metodo del genere è abbastanza semplice da implementare, ma è altrettanto evidente che la presenza di byte di dati o di allineamento presenti all’interno della sezione codice possono compromettere il buon esito del lavoro. Esistono poi disassembler che utilizzano un’altra tecnica: recursive traversal disassemblers, in questo caso questi si inizia a disassemblare dall’entry-point fino alla prima istruzione di salto (jmp, jnz,…) per poi, successivamente, riprendere a decodificare direttamente dal quel punto. Nel primo caso per contrastare il disassembler può essere opportuno inserire dei junk byte, ovvero byte inseriti di proposito nella sezione istruzioni allo scopo di disturbare il processo. Un’altra alternativa è quella di utilizzare i cosiddetti predicati opachi, o opaque predicates, così definiti nel loro lavoro da Linn e Debray; in sostanza, è così definito un predicato che in maniera non ovvia restituisce sempre un valore booleano, true o false. Un predicato di questo tipo è tradotto in codice come un salto senza proseguire in maniera lineare. Esiste poi la possibilità di inserire nel codice dei falsi punti di ritorno. Vale a dire, un disassembler ipotizza sempre che l’istruzione eseguita al ritorno di una funzione è quella immediatamente successiva alla chiamata, ma se si fa in modo di alterare questo schema inserendo magari un junk byte? In questo caso si altera la sequenza di decodifica del codice macchina. Non solo, è possibile anche utilizzare le funzioni indirette insieme ai predicati opachi. Le possibilità offerte sono davvero tante ognuna intende coprire un aspetto ben determinato.

Oggi buona parte dei sistemi embedded dispone della funzionalità secure boot, in grado di garantire che soltanto il codice originale possa essere caricato eseguito dalla memoria flash durante il boot. Anche il modulo ESP32 Wroom che equipaggia ESPertino dispone di questa importante funzionalità, particolarmente utile per contrastare manomissioni o contraffazioni del codice.