
Gli ambienti di virtualizzazione rappresentano le risposte più decise ai requisiti di sicurezza e di affidabilità: elementi essenziali e richiesti sempre con maggiore insistenza dal mercato.
La virtualizzazione, in sé, è un concetto già presente nella realtà; in effetti, i sistemi operativi, e in modo particolare quelli di ultima generazione, prevedono nella loro architettura interna la presenza di meccanismi in grado di assicurare il funzionamento di macchine virtuali, ossia nel simulare uno spazio di memoria maggiore di quello fisicamente presente o nella garanzia di conciliare codice legacy con i nuovi requisiti di sicurezza. Il tutto è garantito grazie all’uso di dispositivi hardware, quali MMU, in una gestione più efficiente dei processi presenti in memoria e nella presenza di un nuovo strato software che permette di gestire una separazione funzionale da differenti esigenze.
Di solito quando si parla di virtualizzazione, in letteratura, si tende a riferirsi alle linee guida messe a punto da Popek e Goldberg, due ricercatori, rispettivamente, dell’Università della California e dell’Università di Harvard. In buona sostanza, al fine di realizzare un ambiente virtuale, è necessario perseguire diverse funzionalità, oltre all’equivalenza, al controllo delle risorse e all’efficienza. Nel primo caso, attraverso l’equivalenza, è necessario garantire il medesimo livello funzionale tra l’ambiente virtuale e una macchina fisica equivalente, mentre, con il controllo delle risorse, l’ambiente di virtualizzazione deve possedere il completo controllo delle risorse virtualizzate; infine, con l’efficienza, occorre garantire che le istruzioni della piattaforma virtualizzata siano eseguibili senza l’intervento dell’ambiente di virtualizzazione. Nella maggior parte dei casi si tende a utilizzare un approccio software, anche se poi si ricorre in realtà a una realizzazione ibrida. In sostanza, per realizzare una virtualizzazione delle risorse si tende a implementare una Virtual Machine Manager (VMM), ossia uno strato di software che si interpone tra l’hardware fisico e le virtual machine. Il fine è quello di implementare un efficiente duplicato di una macchina reale tanto che ogni utente, o programma, di una virtual machine, può installare un diverso sistema operativo e avere l’impressione di essere l’unico utilizzatore dell’intero sistema. Tale tecnica, utilizzata per permettere la condivisione tra più utenti di un’unica macchina, è realizzata grazie a un software chiamato Hypervisor o virtual machine. In definitiva, la virtualizzazione è una tecnologia che consente l’esecuzione, in modo contemporaneo, di più di un sistema operativo perché lo strato software che consente questa particolarità è un hypervisor (equivalentemente noto come monitor della macchina virtuale o VMM). Grazie a questa particolarità, l’Hypervisor può rendere possibili progetti con differenti applicazioni: una sezione che si occupa di computazione, un’altra che gestisce una particolare interfaccia utente e un’altra ancora è orientata ad acquisire ed elaborare segnali. Possiamo senza dubbio affermare che un Hypervisor realizza un livello di astrazione tra l’hardware reale dell’elaboratore, su cui funziona, e l’ambiente virtuale, in modo da far credere di aver a disposizione tutte le risorse hardware: tutti gli accessi sono mediati ricorrendo a un particolare software di interfaccia. L’Hypervisor realizza queste operazioni in diversi modi a seconda del sistema di virtualizzazione utilizzato, oltre a risolvere tutte le eventuali eccezioni che possono accadere quando una virtual machine prova a eseguire un’istruzione privilegiata o quando avviene una failure del sistema. La tecnologia Hypervisor può essere divisa concettualmente in due grandi famiglie (figura 1), a seconda della particolarità utilizzata. Esistono, in prima istanza le macchine virtuali di tipo nativo o bare-metal, ossia le virtual machine sono eseguiti direttamente utilizzando le risorse hardware della macchina host e non si appoggiano ad alcun software sottostante; in questa prospettiva, l’Hypervisor bare-metal è posto in esecuzione senza un sistema operativo che lo ospita con la possibilità di accedere alle diverse risorse hardware. Al contrario, quelle di tipo hosted sono, in realtà, applicazioni che vengono eseguire sulla macchina host ma in modo tale che software di virtualizzazione, Hypervisor e sistema operativo host, siano eseguiti su livelli diversi; in effetti, l’Hypervisor, denominato anche macchina virtuale, lavora su una o più istanze del sistema in cima a un sistema operativo “host”.
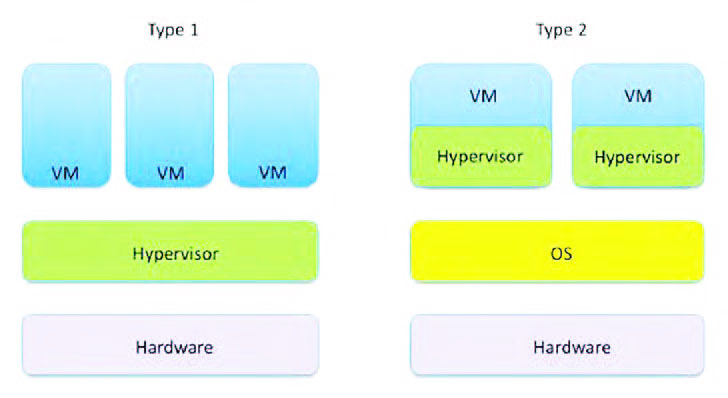
Figura 1: le due proposte virtuali.
Le Virtual Machine
Esistono diverse tecniche fondamentali per realizzare la virtualizzazione Hypervisor. Per esempio, una particolare tecnica presume di sfruttare la traduzione binaria, o binary translation, cambiando le istruzioni privilegiate, ad esempio, al volo in modo che sistemi operativi multipli possano coesistere senza conflitti. In altre parole, la traduzione binaria è la traduzione di un codice macchina da uno specifico codice binario sorgente a un generico codice macchina destinazione. Il codice tradotto è memorizzato ed eseguito a ogni richiesta di un’istruzione privilegiata e la traduzione è, in genere, eseguita a blocchi di codice. Da un punto di vista implementativo, questa tecnica prevede una traduzione a run-time, traduzione dinamica, del codice destinato all’architettura hardware. In pratica, poiché il codice del sistema operativo non viene modificato, tutte le parti di codice che contengono operazioni privilegiate, e che quindi richiedono l’intervento del VMM, devono essere interpretate per inserirvi dei riferimenti alla VM. Questa particolare soluzione introduce però un overhead più elevato. È necessario, al fine di realizzare un’implementazione di questo tipo, inserire, tra processore e macchina virtuale, un interprete. È anche possibile, però, ricorrere a una traduzione statica; in altre parole prima dell’esecuzione viene eseguita una traduzione dal codice sorgente al codice destinazione ed è alternativa a quella dinamica, ossia il codice macchina, attraverso stream di dati esadecimali, viene interpretato in fase di run-time. Un’altra soluzione è ricorrere alla cosiddetta hardware-assist, ossia sul sostegno dell’hardware grazie anche alla tecnologia utilizzata dai processori Intel o AMD (figura 2).
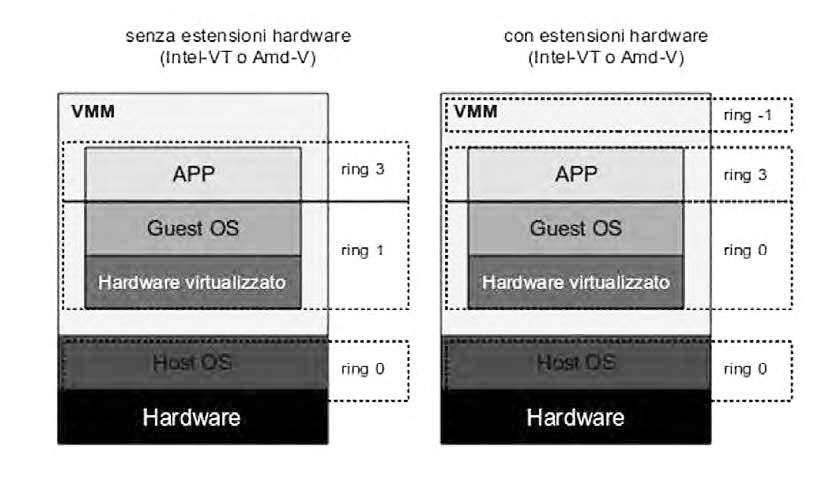
Figura 2: meccanismo assistito dall’hardware.
Da diversi anni i maggiori produttori di CPU di largo consumo hanno introdotto nei propri processori estensioni che facilitano la gestione delle macchine virtuali e consentono di superare il degrado delle prestazioni. In questa particolare tecnica diventa indispensabile gestire e definire un corretto livello di privilegio. In questo caso, i processori dell’architettura IA32 supportano politiche di protezione che utilizzano il concetto di ring. A ogni ring è associato un livello di privilegio: il software eseguito al livello 0 ha privilegi più alti, mentre quello con il livello 3 più bassi. Il livello di privilegio determina, ad esempio, la corretta esecuzione delle istruzioni privilegiate secondo i particolari criteri adottati. Per ottenere il controllo del processore, il sistema operativo deve poter essere eseguito al livello di privilegio 0 ma poiché in un ambiente VMM non è possibile concedere questo livello di controllo a un sistema operativo guest è necessario prevedere un meccanismo che garantisca il controllo di queste attività: in questi casi viene usata la tecnica del ring deprivileging. Non solo, la tecnologia VT-x di Intel, introduce due nuove modalità di esecuzione per il processore: la VMX root operation e la VMX non-root operation. La prima permette di riprodurre, in maniera simile, il comportamento dei processori IA-32 senza VT-x, ed è una modalità di funzionamento pensata a uso del VMM. La seconda modalità di operazione, invece, fornisce un ambiente di esecuzione controllato da un VMM ed è pensata per facilitare la creazione delle macchine virtuali. In entrambe le modalità sono presenti i quattro livelli di privilegio. AMD, al contrario, ha pensato alla sua Pacifica Virtualization Technology: l’istruzione VMRUN permette di passare dalla modalità in cui viene eseguito il flusso di istruzioni dell’“host” a quella in cui vengono eseguite le istruzioni del “guest” e, una volta che il “guest” ha terminato, si ritorna all’istruzione dell’“host” seguente la VMRUN. La tecnologia IntelVT consente alla CPU di agire come se il sistema fosse dotato di più CPU che lavorano in parallelo e questo rende possibile l’esecuzione di più sistemi operativi contemporaneamente sulla stessa macchina fisica. Intel-VT estende il set ISA con diverse nuove istruzioni specificatamente realizzate per la virtualizzazione, quali VMPTRLD, VMREAD o VMPTRST. Esiste anche la nuova modalità operativa chiamata VMX root nella quale il VMM è eseguito con privilegi massimi, eliminando la necessità di deprivilegiare il kernel del sistema operativo guest che opera nella modalità VMX non–root. Esiste un’altra possibilità: la paravirtualizzazione, ossia alcuni Hypervisor forniscono alcune API che gli sviluppatori possono utilizzare per chiamare i suoi servizi. Questa tecnica, chiamata paravirtualizzazione, può portare a prestazioni superiori rispetto alle precedenti, quali traduzione binaria o assistenza dell’hardware. In questo modo, l’Hypervisor mostra alle macchine virtuali una versione virtuale dell’hardware sottostante, mantenendone tuttavia la medesima architettura di quella reale, quindi si ha qualche similitudine con il sistema precedente, ma si rende necessario modificare il sistema operativo in esecuzione sulle macchine virtuali per evitare l’esecuzione di alcune particolari istruzioni privilegiate. Non viene invece modificata l’Application Binary Interface (ABI) e ciò consente di eseguire le applicazioni senza modifiche.
Virtual embedded
La presenza di un Hypervisor in un sistema embedded aggiunge flessibilità e una capacità superiore offrendo maggiore robustezza e funzionalità. In particolare, un Hypervisor è un particolare tipo di sistema operativo che viene eseguito direttamente sull’hardware: crea un’astrazione della piattaforma hardware sottostante in modo che possa essere utilizzata da una o più macchine virtuali (VM) senza sapere nulla delle macchine virtuali che condividono la piattaforma. Una VM, in questo contesto, è semplicemente un contenitore per un sistema operativo e delle sue applicazioni. In questo modo una macchina virtuale è isolata da altre macchine virtuali in esecuzione sull’Hypervisor tanto che possono esserci più sistemi operativi, o meccanismi supporto per i sistemi operativi, con configurazioni diverse.
Le proposte
Esistono diverse proposte: da soluzioni open source fino a quelle più squisitamente commerciali. Xen, ad esempio, è composto da un Hypervisor che permette di eseguire diversi sistemi operativi sulla stessa macchina, in maniera concorrenziale: il sistema di virtualizzazione non è installabile su un sistema operativo già configurato, ma lo sostituisce prendendo direttamente il controllo dell’hardware della macchina. Questo consente un consumo minimo di risorse ed elevate performance. Kernel-based Virtual Machine, o KVM, è un sistema di tipo full-virtualization esclusivamente per GNU Linux, su piattaforma x86 ed è già presente nella maggior parte delle distribuzioni installate nei PC. Usando KVM possono essere eseguite più virtual machine basate su GNU Linux o Microsoft Windows senza modificarne le immagini e ogni virtual machine ha il suo hardware virtualizzato. VMware è stata la prima azienda a proporre un prodotto volto alla virtualizzazione e, attraverso l’utilizzo di driver standard, permette la portabilità delle macchine virtuali tra più sistemi. Per le applicazioni più squisitamente embedded possiamo, senza dubbio, ricordare PikeOs o LynuxWorks.
PikeOs
PikeOS è una piattaforma messa a punto per realizzare lo sviluppo di sistemi embedded, dove più sistemi operativi e applicazioni possono essere messe in esecuzione in modo simultaneo in un ambiente definito sicuro. L’architettura PikeOS si basa su un microkernel compatto ed estremamente ridotto con una serie di servizi in grado di assicurare la gestione di ogni funzionalità. In PikeOs sono utilizzati di due concetti, ovvero task e thread. Nel primo caso, con thread si suole identificare una porzione di codice che, ogni volta che viene messo in esecuzione dal kernel, ha il pieno accesso ai dati e allo stack: in sostanza, il thread è l’entità di base nel contesto PikeOs. Ad ogni thread è associata una time partition, mentre un task è, tipicamente, una resource partition. Al contrario, un task identifica uno spazio diverso, ossia un address space distinto e condiviso da tutti i thread che utilizzano quel task. Il kernel di PikeOs offre un multitasking con uno scheduling di tipo priority-based con il pieno supporto della gestione delle risorse. Il software di sistema di PikeOS (PSSW) offre diversi servizi al pari di un comune sistema operativo commerciale e garantisce anche la gestione delle partizioni, ossia ambienti sicuri dove poter eseguire applicazioni dedicate e magari costruiti con diversi sistemi operativi. In PikeOs il software di sistema, al momento del boot, definisce la configurazione dell’ambiente di lavoro recuperando i parametri per tutti i servizi PSSW dalla tabella di inizializzazione della macchina virtuale (VMIT). Gli errori che si verificano durante questo stato sono riportati al sottosistema del PSSW o al software di monitoring. Al termine della fase di configurazione iniziale alle singole partizioni sono assegnate le risorse richieste e successivamente si pone in esecuzione un processo demone. Il processo è posto in esecuzione in base a proprietà definite in modo statico già in fase di inizializzazione del sistema, in accordo alle informazioni riportate nella VMIT, rispettando tempi e il partizionamento. Successivamente tutti i processi applicativi sono inseriti in memoria e posti in esecuzione, se richiesto. Le diverse applicazioni presenti possono usufruire dei servizi PSSW per mezzo dell’apposita libreria. In definitiva, PikeOS è, senza dubbio, un’architettura interessante perché implementa in primo luogo quello che viene chiamato una separazione del kernel: come un Hypervisor, una partizione del kernel isola in modo sicuro gli ambienti per gli ospiti, guest, di livello superiore. PikeOS viene utilizzato, tipicamente, nel settore avionico per applicazioni safety-critical (figura 3).
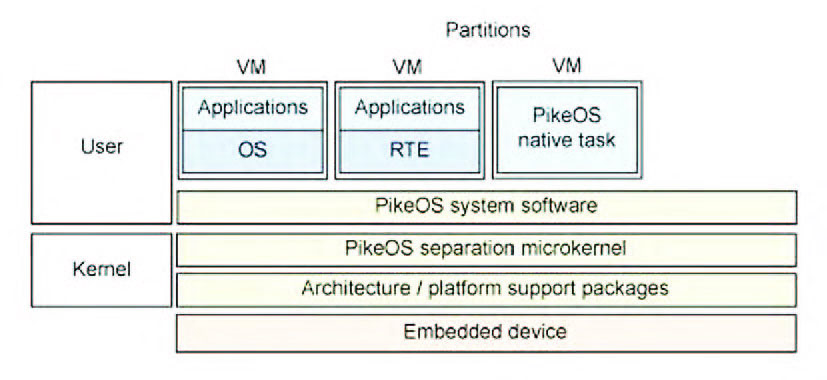
Figura 3: PikeOs.
All’interno dello spazio riservato al kernel, PikeOS implementa una serie di pacchetti software di supporto per l’architettura e la piattaforma utilizzata: da x86 a PowerPC passando per SuperH. PikeOS supporta non solo i sistemi operativi guest (con le applicazioni associate), ma può anche gestire ambienti per un dominio specifico (come l’interfaccia nativa PikeOS o il real-time di Java). Lo strato software di sistema di PikeOS alloca le risorse (in termini di spazio e di tempo) per le applicazioni definite come guest. SysGo è anche in grado di assicurare il supporto verso Android come sistema operativo Guest o “Personality”. Grazie a questa nuova possibilità, la tecnologia PikeOS permette alle applicazioni Android di funzionare in concomitanza con gli altri ambienti esecutivi rispettando i requisiti di sicurezza e permettendo il partizionamento stretto tra le applicazioni critiche e non critiche. Gli sviluppatori di Android possono ora combinare i requisiti di real-time con il codice legacy o protetto. Con le ultime versioni di PikeOs si intende assicurare la possibilità di utilizzare multipli OS interfaces, chiamate Personalities, e di lavorare su gruppi separati di risorse all’interno di una singola macchina. Tra le Personalities possiamo ritrovare pacchetti quali Linux, POSIX, RTEMS, ARINC-653. Per via della separazione delle risorse imposte dal microkernel PikeOS, diverse applicazioni con requisiti differenti in fatto di sicurezza e appartenenti ad altre Personalities sono in grado di coesistere sulla stessa piattaforma hardware.
Lynuxworks
LynxSecure di LynuxWorks rappresenta la risposta più diretta che l’azienda americana offre per il mercato embedded (figura 4).
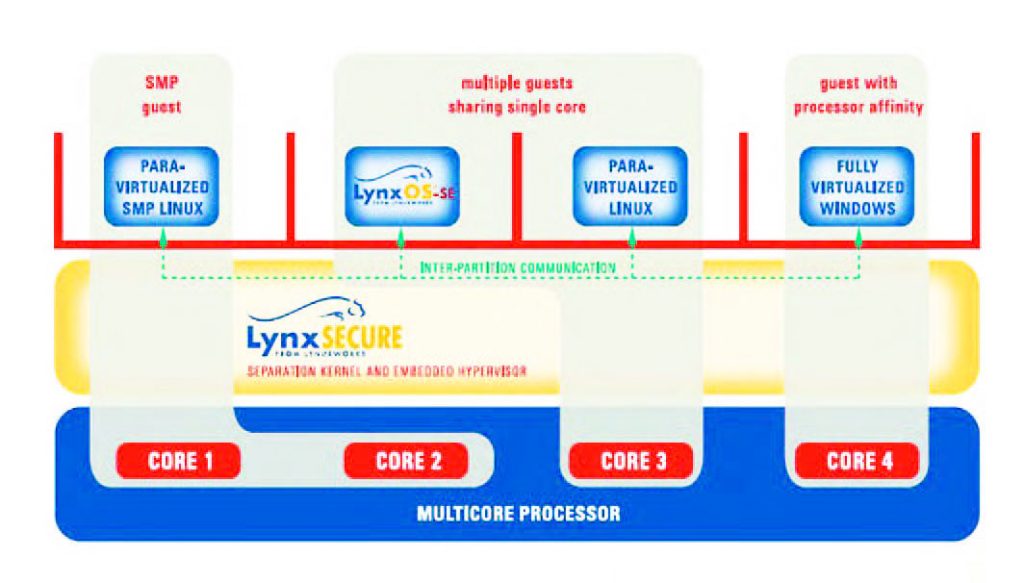
Figura 4: LynxSecure.
In base alle specifiche emesse dal produttore LynxSecure può girare su qualsiasi processore a 32-bit o 64-bit con MMU e assicura un elevato grado di compatibilità binaria tra un sistema operativo stand-alone e la sua versione virtualizzata. LynxSecure si basa su standard aperti, ma offre anche un estremo grado di sicurezza e funzionalità aderendo allo standard MILS ed è stato realizzato per essere certificabile a EAL 7 +. In realtà LynyxWorks commercializza diverse proposte in grado di rispondere a differenti requisiti. Pensiamo a LynxOs che si rivolge al segmento hard real-time e assicura anche la compatibilità Abi, Application Binary Interface, ed è pienamente conforme Posix. Non solo, la variante LynxOS-Se, sempre della categoria hard real-time, assicura anche la rispondenza agli standard quali Arinc 653 e Posix ed è particolarmente rivolto alle realizzazioni di tipo multi partizione. Ad ogni modo, LynxSecure offre anche una connettività integrata di rete consentendo alle applicazioni di comunicare in modo trasparente via TCP/IP con altri sistemi operativi virtualizzati, come Linux, in esecuzione in una partizione separata. Questa sicura comunicazione intra-partizione è gestita interamente da LynxSecure, senza modificare le applicazioni o il sistema operativo virtualizzato. LynxSecure 3.1 introduce il supporto verso Windows 7, Windows Vista e Windows 2003, che sono gestiti come sistemi operativi guest completamente virtualizzati, aggiungendo al già precedente supporto di Windows XP offerto nella versione 3.0.
