
La virtualizzazione di più sistemi operativi su una singola macchina è sicuramente uno degli argomenti piu ‘hot’ nel campo delle applicazioni per PC, ma è ancora fonte di discussione nel settore dei sistemi embedded.
Le particolari esigenze in termini di determinismo e di bassa latenza nella risposta del sistema, rendono necessario adottare dei software studiati appositamente, e richiedono anche un’attenzione particolare nella configurazione dell’hardware della macchina. Nell’articolo saranno esposti i principi di funzionamento dei software per la virtualizzazione per sistemi embedded ed alcuni software commerciali che rispondono a queste esigenze.
GLI OBIETTIVI DELLA VIRTUALIZZAZIONE
Lo scopo della virtualizzazione, in generale, è quello di permettere l’esecuzione contemporanea su una singola macchina di più sistemi operativi, in modo tale che questi condividano le risorse hardware della stessa in maniera trasparente. Ciò significa che ogni sistema operativo deve poter accedere alle risorse come la CPU, la RAM, gli Hard disk e le interfacce di I/O, senza interferire con gli altri SO in esecuzione. Ad esempio, in un sistema virtualizzato può essere necessario condividere una singola scheda di rete Ethernet tra più SO. In questo caso il software di virtualizzazione deve incorporare un driver per gestire la scheda di rete mentre dovrà presentare ai singoli SO una emulazione della scheda, in maniera che questi possano accedervi in maniera trasparente. Per poter ottenere gli obiettivi della virtualizzazione, è necessario che sulla nostra macchina venga installato un particolare software, detto Virtual Machine Monitor (VMM) o Hypervisor, che si occupa di gestire l’assegnazione delle risorse ai diversi SO. Il VMM trasforma il sistema in una serie di macchine virtuali ciascuna delle quali è assegnata ad un singolo SO. Un dato SO quindi vedrà solo la sua macchina virtuale senza avere conoscenza dell’esistenza di altri SO in esecuzione.
ARCHITETTURA DI UN SISTEMA VIRTUALIZZATO
Le architetture di base di un VMM sono due:
# Hosted: il VMM si appoggia ad un SO preesistente per la gestione degli I/O e lo scheduling dei processi. È questo il caso del noto VMWare Workstation, largamente utilizzato in ambito PC. Nel caso dei sistemi embedded però, una tale soluzione non è accettabile in quanto non assicura il funzionamento in real-time del sistema. Uno schema di base di questa architettura è riportato in figura 1.
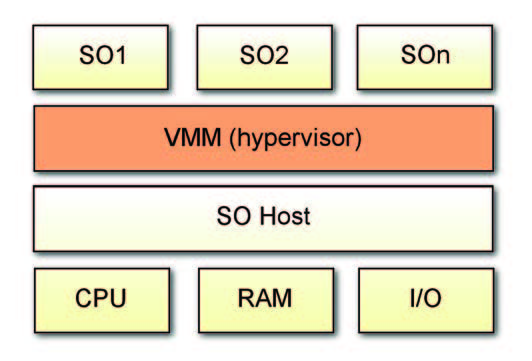
Figura 1: schema a blocchi di un sistema
virtualizzato con VMM Hosted.
# Bare Metal: in tale approccio il VMM non utilizza alcun SO preesistente, ma accede alle risorse hardware direttamente interponendosi tra di esse ed i SO per così dire ‘ospitati’ nella macchina. È il sistema adatto per le applicazioni che richiedono l’uso di SO realtime, come avviene generalmente nel caso dei sistemi embedded di controllo. Inoltre, un VMM bare metal permette (se la sua architettura lo consente, come vedremo più avanti) a ciascun SO di utilizzare i propri driver nativi per la gestione degli apparati di I/O. In figura 2 è riportato lo schema di un tale sistema. Nel seguito ci riferiremo pertanto all’analisi di hypervisor bare metal.
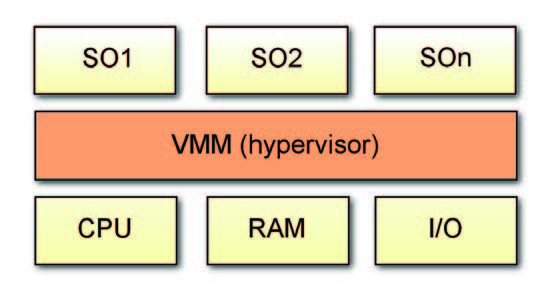
Figura 2: schema a blocchi di un sistema virtualizzato con Hypervisor Bare Metal.
LE ISTRUZIONI PRIVILEGIATE ED IL RUOLO DELL’ HYPERVISOR
In un sistema virtualizzato, dunque, le applicazioni (che siano o meno Real Time) sono eseguite dai SO ospitati nella macchina. Quando deve intervenire l’hypervisor durante il normale funzionamento dei SO? Ogni qual volta venga richiesto l’utilizzo delle cosiddette istruzioni privilegiate della CPU. Queste sono le istruzioni impiegate per lo scheduling dei processi in un SO multitasking/multithreading, per l’accesso alle risorse hardware come la RAM ed i dispositivi di I/O, ad esempio gli apparati di rete, e per il controllo della CPU (ad esempio l’istruzione di halt). I metodi utilizzabili da un VMM per svolgere i suoi compiti sono i seguenti
# Binary translation: il codice eseguibile (binario) del SO viene tradotto al volo in modo da richiamare le funzioni del VMM quando è richiesta l’esecuzione delle istruzioni privilegiate.
# Assistito dall’hardware: in questo caso, quando è richiesta l’esecuzione di istruzioni privilegiate, il VMM viene richiamato direttamente dalla CPU provvista di funzionalità di virtualizzazione. Ad esempio le funzionalità Intel-VT e AMD-V dei più recenti processori Intel ed AMD.
# Paravirtualization: il codice sorgente del SO è modificato appositamente dal fornitore dell’hypervisor in modo da richiamare il VMM quando necessario. Questa opzione è ovviamente praticabile solo nel caso di SO open source, ad esempio Linux.
LA SOLUZIONE HARDWARE
Con la diffusione dei software per la virtualizzazione, Intel ed AMD hanno sviluppato una soluzione hardware alle problematiche viste. In pratica, le nuove CPU dotate delle funzionalità Intel-VT o AMD-V, sono provviste di ulteriori set di registri interni appositamente dedicati alla virtualizzazione, ed inoltre aggiungono un nuovo livello di privilegio detto livello root -che potremmo intendere anche come ‘Ring -1’ livello al quale sarà eseguito il VMM. In questo caso, quindi, i SO virtualizzati continueranno ad essere eseguiti al livello 0, mentre il VMM eseguirà le sue operazioni al livello root. Il passaggio da un livello all’altro avviene tramite due comandi:
VM entry: con questo comando i SO possono eseguire le istruzioni non root. VM exit: il SO cede il controllo al VM che può quindi eseguire le istruzioni root. Queste soluzioni hardware risolvono le problematiche che abbiamo visto esistere con le soluzioni software. Attualmente la maggior parte dei VMM sia per PC che per sistemi embedded è in grado si utilizzare queste nuove funzionalità delle CPU.
PER UN HYPERVISOR EFFICIENTE: PARTIZIONARE LE RISORSE
Dal punto di vista prestazionale, è opportuno evidenziare che l’impatto dell’esecuzione del VMM è simile ad un context switching tra applicazioni in un SO multitasking. In pratica, ogni qual volta il VMM deve intervenire, è necessario memorizzare lo stato del SO attualmente in esecuzione per poterlo poi recuperare alla fine. É quindi necessario cercare di minimizzare il più possibile l’intervento del VMM al fine di evitare una riduzione eccessiva delle prestazioni del sistema. Una possibile soluzione consiste nel partizionamento delle risorse hardware del sistema tra i diversi SO in esecuzione. In pratica si cerca di assegnare ad ogni SO un insieme delle varie risorse (core, memoria, dispositivi di I/O) in maniera esclusiva in modo tale da non richiedere – o comunque da minimizzare – l’intervento del VMM.
PARTIZIONAMENTO DEI CORE
Se il sistema possiede una (o più) CPU multicore, come nel caso delle moderne CPU Intel Core 2, Intel Xeon e simili, è possibile assegnare uno o più core ad un singolo SO. In questo caso non sarà necessario l’intervento del VMM per lo scheduling dei processi eseguiti su un dato core, alleggerendo il compito del VM e migliorando notevolmente le prestazioni del sistema virtualizzato. In ogni caso, è da tenere presente che le prestazioni del sistema saranno sempre inferiori rispetto a quelle di un sistema non virtualizzato.
PARTIZIONAMENTO DELLA MEMORIA
Sempre se la particolare implementazione del VMM lo permette, è anche possibile partizionare la memoria RAM del sistema tra i diversi SO assegnando a ciascuno di essi una porzione specifica della memoria fisica. In questo caso non sarà necessario che il VMM si occupi della traduzione degli indirizzi.
PARTIZIONAMENTO DEGLI I/O
Anche i dispositivi di I/O possono essere partizionati tra i SO. Il partizionamento di questi dispositivi in questo caso richiede qualche attenzione in più: normalmente, infatti, gli apparati di I/O comunicano con il SO attraverso interrupt, interrupt che dovrebbero essere gestiti dal VMM in quanto richiedono l’uso di istruzioni privilegiate della CPU. È quindi necessario eseguire un appropriato routing degli interrupt, cosa che in certi casi richiede l’assegnazione fisica delle linee di IRQ ai diversi dispositivi. Ciò dipende in ogni caso dalla particolare struttura hardware del sistema.
I/O SHARING O PARTIZIONAMENTO: DIFFERENZE PRESTAZIONALI E DRIVER
Approfondiamo con un confronto quali sono le differenze dal punto di vista dell’architettura del VMM e delle prestazioni del sistema virtualizzato tra i due casi di condivisione o di partizionamento dei dispositivi di I/O. Nel caso in cui il VMM supporti la condivisione dei dispositivi, dovrà ovviamente prendersi carico di tutte le chiamate di I/O da parte dei SO. In aggiunta, dovrà gestire gli interrupt generati dal dispositivo. Tutti questi compiti sono normalmente svolti dal driver dell’apparato, fornito con il particolare SO che dovrà utilizzarlo. Ma nel caso di un apparato condiviso, il VMM dovrà implementare esso stesso il driver, cosa che comporta ovviamente dei tempi di sviluppo (e dei costi) notevolmente superiori. Oltretutto, potrebbero non essere disponibili driver per apparati custom, sviluppati ad esempio per essere utilizzati con un SO real time, come particolari dispositivi di acquisizione dati e/o di con trollo automatico. Oltre ad implementare il driver, il VMM deve presentare a ciascun SO un’emulazione dell’hardware da condividere in maniera che ogni SO possa accedere all’apparato in maniera trasparente, come se fosse sotto il suo controllo. Ogni chiamata del dispositivo da parte del SO ed ogni interrupt che parte dal dispositivo stesso dovranno essere gestite dal VMM con un chiaro overhead delle prestazioni. In conclusione, la condivisione dell’hardware comporta un aumento della complessità nello sviluppo del VMM ed una diminuzione delle prestazioni del sistema virtualizzato. Al contrario, in un sistema nel quale gli apparati di I/O siano partizionati e quindi assegnati in esclusiva ad uno dei SO, questi potranno continuare ad utilizzare i loro driver nativi per espletare le funzioni di I/O e per rispondere agli interrupt generati dai dispositivi hardware. Il VMM dovrà solo intercettare le chiamate d’istruzioni privilegiate dei singoli SO e le richieste di interrupt e direzionarle verso l’apparato corretto. Inutile dire che in un tale scenario le prestazioni del sistema risultano più elevate, mentre è notevolmente semplificato lo sviluppo del VMM, permettendo inoltre l’utilizzo di driver specifici ed aumentando così l’affidabilità e la stabilità del sistema.
UN ESEMPIO DI VMM:NI REAL TIME HYPERVISOR
National Instrument, produttore della nota suite LabVIEW, ha sviluppato un software di virtualizzazione denomina to Real-Time Hypervisor. Questo hypervisor permette di utilizzare sulla stessa macchina Windows XP ed il SO LabVIEW Real-Time di NI. Tale sistema operativo è stato sviluppato in particolare per i sistemi della serie PXI (PCI eXtensions for Instrumentation) ed i controller industriali prodotti da NI. Permettendo l’uso contemporaneo di Windows XP e di LabVIEW Real-Time, l’hypervisor permette di utilizzare applicazioni altrimenti non disponibili sui suoi controller pur mantenendo le caratteristiche deterministiche proprie di un SO Real-Time.
ARCHITETTURA DI NI REAL-TIME HYPERVISOR
Real-Time Hypervisor è un VMM di tipo bare metal, che si interpone quindi direttamente tra i SO host e l’hardware del sistema. Utilizza una tecnologia di virtualizzazione a basso livello denominata VLX. Come sappiamo, l’hypervisor viene richiamato quando uno dei due SO virtualizzati richiede di accedere ad una risorsa condivisa, ma anche nel caso che cerchi di comunicare con l’altro SO al fine di condividere dati. Questo hypervisor utilizza il supporto hardware alla virtualizzazione Intel-VT integrato nei processori Intel. Nel caso in cui sia utilizzato sui controller dotati di CPU multicore (attualmente i modelli NI PXI-8108, NI PXI-8110 e NI 3110), l’hypervisor di NI partiziona i core tra i due SO assegnando un core ad XP ed i restanti (1 o 3) a LabVIEW Real-time. Anche la memoria RAM può essere partizionata tra i due OS, così come i moduli di I/O del sistema. L’assegnazione è eseguita tramite una utility denominata Real-Time Hypervisor Manager. Come abbiamo visto, partizionare le risorse diminuisce l’hoverhead dovuto al context swithching che sarebbe altrimenti necessario ogni volta che l’hypervisor dovesse intervenire per assegnare la risorsa ad uno dei due SO. I controller industriali e PXI possiedono quattro linee fisiche di interrupt request (PIRQ) come definite dallo standard PCI. Queste quattro linee sono presenti nel backplane sul quale vanno inseriti i moduli di I/O, in modo da portare i segnali di interrupt generati dai dispositivi verso il controller. Tramite la utility di configurazione, è possibile assegnare ciascuna delle linee fisiche di IRQ ad uno dei due SO. Ciò significa che i moduli di I/O che usano una linea assegnata ad un dato SO saranno a loro volta assegnati allo stesso. Può essere quindi necessario spostare fisicamente un dato modulo in modo da far corrispondere la sua linea fisica di IRQ a quella assegnata ad un dato SO. In ogni caso non tutte le possibili assegnazioni sono possibili, ma vengono comunque segnalate dalla utility di configurazione.
INTERRUPT LATENCY E PRESTAZIONI
Ogni volta che l’hypervisor riceve un interrupt da un dispositivo di I/O deve intervenire per direzionarlo verso il SO che dovrà elaborarlo. Ciò introduce una certa latenza che può parzialmente ridurre le caratteristiche deterministiche di un SO Real-Time. Questo è vero soprattutto per gli interrupt ad alta frequenza, diciamo maggiori di 5 KHz, tipici di alcuni sistemi di acquisizione dati e controllo. In questi casi si assiste ad una diminuzione notevole delle prestazioni. Un miglioramento notevole lo si può avere nel caso in cui sia possibile utilizzare il polling anziché un interrupt, come nel caso dell’acquisizione di blocchi di dati di grandi dimensioni.
COMUNICAZIONE TRA I SO
Per rendere possibile la comunicazione tra i due SO, si possono utilizzare due schede Ethernet una delle quali assegnata ad XP e l’altra a LabVIEW. In questo modo lo scambio di dati è effettuato utilizzando tecniche usuali di Inter-Process Communication che si avvalgono di variabili condivise e dei protocolli TCP/IP per il trasporto dei dati. Come alternativa, NI Real-Time Hypervisor mette a disposizione un’interfaccia Ethernet virtuale che appare sia in XP che in LabVIEW come se fosse un adattatore fisico reale con un proprio indirizzo IP. In tal caso però, oltre all’overhead dovuto all’utilizzo degli interrupt da parte dell’interfaccia di rete -che sia fisica o virtualesi aggiunge un ulteriore overhead dovuto al calcolo in software del checksum dei pacchetti (altrimenti eseguito dall’hardware dell’adattatore di rete). In definitiva, l’uso di un tale sistema di comunicazione permette un throughput dei dati che corrisponde a circa un terzo di quello che si può ottenere con una scheda fisica in un sistema non virtualizzato. NI suggerisce a tale scopo di dedicare, se disponibili, uno dei core alle comunicazioni che richiedono interrupt, come appunto la scheda di rete, ed un altro core a quelle che funzionano tramite polling, ottenendo in questo caso un miglioramento del throughput fino a tre volte.
UN ALTRO ESEMPIO DI VMM: WIND RIVER HYPERVISOR
Wind River è un’azienda specializzata in soluzioni Real-Time per sistemi embedded. Di recente è stata acquisita da Intel, nell’ottica di garantire una maggiore penetrazione della multinazionale statunitense nel mercato embedded high-end. Wind River Hypervisor è un VMM di tipo 1 (vale a dire bare metal) con un architettura ottimizzata per poter garantire prestazioni deterministiche ed una bassa latenza nella gestione degli interrupt, adatto quindi ad applicazioni Real-Time. Questo VMM è stato concepito per essere integrato con il SO Real Time VxWorks della stessa Wind River, accanto ad un SO general purpose come in particolare Wind River Linux. Sono tuttavia supportabili altri SO. Wind River Hypervisor supporta processori Intel e Power PC, ed è in grado di utilizzare le estensioni hardware per la virtualizzazione incluse nella CPU, se disponibili. Anche questo hypervisor è in grado di partizionare tra i diversi SO le risorse hardware del sistema: CPU (eventualmente multicore), memoria e dispositivi di I/O, presentando agli stessi una virtual board. Se necessario, supporta la condivisione di CPU e dei dispositivi di I/O. In particolare può condividere un solo core tra più SO implementando una virtualizzazione dei core. Particolarmente curato è il supporto al debugging delle applicazioni facente uso di tool specifici di Wind River, così come gli strumenti per la comunicazione tra i diversi SO. Vediamo di seguito alcune delle altre caratteristiche peculiari di questo hypervisor
# Virtual board interface: Interfaccia che permette di ospitare tramite l’hypervisor sia SO che applicazioni che non richiedono l’uso di un SO.
# Build tools: semplificano il build di sistemi multi-OS tramite Wind River Workbench.
# Debugging tools: debug di virtual board tramite una scheda Ethernet fisica e debugging delle applicazioni per VxWorks e Wind River Linux.
# Comunicazione: fornisce degli strumenti di MIPC (multicore/multi-OS IPC), un protocollo a scambio di messaggi per la comunicazione tra i core ed i diversi SO. Questo protocollo usa un’interfaccia tipo socket e memoria condivisa in maniera efficiente.
# On-chip debugging: debug dell’intero sistema o di un singolo SO hosted, tramite il tool Wind River Workbench On-Chip Debugging.
Le problematiche relative alle prestazioni dei dispositivi di I/O sono del tutto analoghe a quelle viste per NI RealTime Hypervisor.
CONCLUSIONI
Quando è utile un sistema virtualizzato Mentre nell’ambito PC la virtualizzazione sta diventando quasi di uso comune, permettendo l’utilizzo contemporaneo di più sistemi operativi come Windows e Linux e soprattutto la condivisione istantanea dei dati, nel caso dei sistemi embedded le richieste molto più stringenti in termini di determinismo e di bassa latenza per le applicazioni real-time tipiche di questi dispositivi, ne hanno finora limitato l’utilizzo. Tuttavia, la crescente diffusione di CPU multicore e lo sviluppo di Hypervisor specializzati come quelli che abbiamo qui analizzato, dovrebbero portare ad un significativo incremento di questa tecnologia anche in quest’ambito. Il poter disporre contemporaneamente, su un sistema nato per scopi di controllo e/o acquisizione dati, di SO per uso generale, permette ad esempio di rendere disponibili una enorme serie di applicazioni, dotate generalmente di interfacce user-friendly, che non sarebbe possibile o conveniente sviluppare ad hoc su SO real-time. Analogamente, il SO real-time rimane dedicato alla gestione di apparati, eventualmente custom, che necessitano un controllo deterministico. Tutto ciò si traduce in una diminuzione dei costi e dei tempi di sviluppo del sistema.


Le macchine virtuali sono una grande comodità, soprattutto se si lavora con diversi sistemi e diverse versioni di sistema operativo. Se si passa ad esempio da un ambiente di sviluppo ad un altro (oppure a una versione dello stesso più recente) può avere senso creare una machcina virtuale con una “fotografia” del sistema correntemente utilizzato. Se un domani vi fosse la necessità di modificare un progetto sviluppato con quel particolare ambiente, sarà sufficiente caricare la macchina virtuale salvata a suo tempo.
Una virtualizzazione embedded può fornire funzionalità native di Windows, che possono essere combinate con software real time ed embedded sullo stesso sistema.