
L’Embedded Microprocessor Benchmark Consortium (EEMBC) ha l'obiettivo di sviluppare misure di riferimento per la stima delle prestazioni di processori e compilatori in applicazioni embedded. Grazie agli sforzi combinati dei suoi membri, i benchmark EEMBC sono presto divenuti uno standard industriale nella stima delle prestazioni dei dispositivi in accordo ad obiettivi ben definiti e criteri application-based. Fin dalla prima certificazione rilasciata (risalente all’Aprile 2000), la valutazione EEMBC ha effettivamente soppiantato il più obsoleto Dhrystone MIPS. A differenza del Dhrystone MIPS che riassume in un unico indice (il MIPS, appunto) le prestazioni di un processore indipendentemente dall’applicazione, l’EEMBC prevede una serie di test che riflettono, in modo piuttosto realistico, le reali condizioni di lavoro del dispositivo che ovviamente dipendono dall’applicazione.
INTRODUZIONE
I test previsti sono rivolti alla misura di prestazioni in campo industriale/automotive (AutoBench), digital entertainment (DENBench), office e networking (OABench) e telecomunicazioni (TeleBench). Oltre a questi è prevista anche una suite (GrinderBench) utilizzata per la misura del benchmark in applicazioni Java J2ME. Esiste anche un ulteriore indice (EnergyBench) che dà una stima del consumo energetico richiesto per lo svolgimento di un determinato task. I risultati vengono certificati dal Consorzio ripetendo i test presso i propri centri; la certificazione garantisce che i test sono ripetibili e condotti secondo le linee guida EEMBC. Gli indici di prestazione vengono ottenuti da test standard e classificati come out-of-the-box o come Full Fury. Nel primo caso l’indice viene ottenuto facendo girare una apposita routine in C senza introdurre alcun livello di ottimizzazione da parte del compilatore. Nel secondo caso invece il codice viene compilato abilitando l’ottimizzazione da parte del compilatore. Ovviamente, mentre l’indice calcolato come out-of-the-box è alquanto significativo, quello ottenuto come Full Fury indica quanto possano essere migliorate le prestazioni ottimizzando il codice.
AUTOMOTIVE/INDUSTRIAL BENCHMARKS
Per ottenere l’indice AutoBench, viene utilizzata una suite di 16 algoritmi tipici di applicazioni industriali e automotive comprendenti: modulazione PWM, conversioni tooth-to-spark e angle-to-time, trasformata iDCT (inverse Discrete Cosine Transform), FFT e filtraggio FIR. La tabella 1 mostra i risultati dei test fatti negli anni passati per un certo numero di microcontrollori: oltre ai singoli indici, viene mostrato anche il valore dell’AutoMark che tiene conto dei risultati di tutti i test.
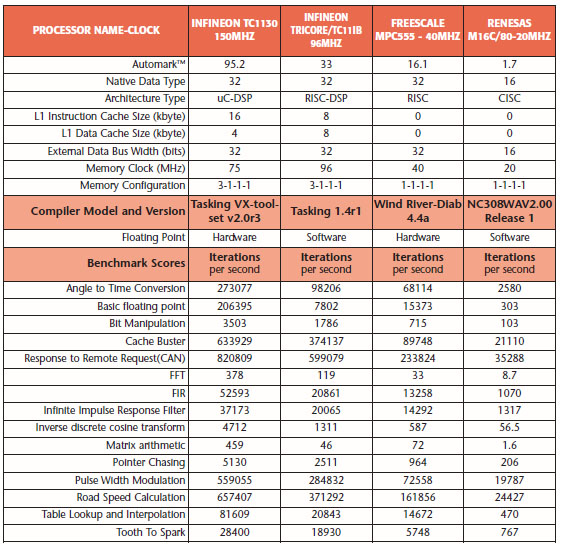
Tabella 1. Risultati dei test per una serie di microcontrollori
NETWORKING BENCHMARKS
La misura delle prestazioni in campo networking, prevede l’uso di algoritmi OSPF/Dijkstra (ampiamente utilizzati nei router), algoritmi Patricia IP (utilizzati nei router per il lookup di indirizzi IP o per la ricerca nei database), tre diversi flussi di pacchetti dati (richieste dallo standard RFC 1812 per i router), algoritmi di IP Network Translator, Quality Of Service (QOS) e TCP. Per il TCP sono previsti, in particolare, tre tipi di test che riflettono le condizioni di funzionamento in altrettanti ambienti tipici delle reti: Gigabit Ethernet, standard Ethernet e TCP Mixed (per la misura di performance in condizioni di traffico misto).
DIGITAL ENTERTAINMENT
L’indice DENBench viene ottenuto utilizzando algoritmi tipici di applicazioni multimediali e gestione immagini. In una macchina fotografica digitale il sensore CCD invia i dati alla CPU che riconverte in formato JPG, per questo motivo vi sono due test atti alla misura delle performance nella compressione e decompressione JPG. Per la misura della risposta della CPU a fronte di calcoli aritmetici e matriciali, viene utilizzato anche un algoritmo per l’implementazione di un filtro passa-alto a scala di grigi. Altri tipi di test sono volti alla valutazione delle prestazioni in applicazioni audio e video implementando algoritmi di compressione e decompressione MPEG-2 e MPEG-4. L’indice tiene conto anche di algoritmi di encryption/decription usati frequentemente in applicazioni eCommerce e Digital Rights Management (DRM).
TELECOM BENCHMARKS
L’indice TeleBench viene calcolato utilizzando cinque algoritmi tipici dei modem e applicazioni xDSL ovvero: autocorrelazione, bit allocation, FFT e iFFT, decodifica Viterbi e decoder a convoluzione. Per quanto riguarda l’autocorrelazione, la suite di prova simula perfettamente una applicazione di telefonia embedded sottoponendo il processore a pesanti operazioni di moltiplicazione e somma. La CPU comprime traffico voce a 8Ks/sec in un formato più compresso. I coefficienti di autocorrelazione vengono calcolati con un algoritmo CELP (Code-Exited Linear Prediction) e vengono prodotti risultati inerenti a tre differenti tipi di segnale: impulsi, sinusoidi e voce. Le prove per il decoder a convoluzione simulano una funzione tipica delle applicazioni embedded impieganti modem basati su standard V.xx. In una applicazione di questo tipo vengono usati come decoder degli shift register che producono uno stream dati in uscita con la possibilità di individuazione e correzione di errore. Gli altri test sono dedicati alle applicazioni ADSL. Il bit allocation misura le prestazioni nello spostare uno stream dati attraverso una serie di buffer. iFFT (inverse Fast Fourier Transformer) prevede la conversione dal dominio della frequenza a quello del tempo, mentre il test FFT prevede l’operazione opposta. Entrambi prevedono una serie di operazioni piuttosto complesse e numerosi accessi alla memoria.
ENERGYBENCH: LE PRESTAZIONI SUI CONSUMI
Ciascuna casa costruttrice di microcontrollori ha il proprio metodo di misura dei consumi per i propri dispositivi. Questo rende praticamente impossibile per un progettista, comparare i vari valori dal momento che i metodi di misura sono i più disparati. L’indice EnergyBench permette di ovviare a questo inconveniente in quanto offre una misura dell’energia consumata dal processore durante l’esecuzione di una applicazione vera e propria (ed indipendente dalla casa costruttrice) evitando quindi l’uso di test arbitrari. Tale misura viene implementata da EEMBC utilizzando la piattaforma LabView ed una scheda di acquisizione dati anch’essa di National Instruments. In figura 1 è mostrato il collegamento tra la scheda di acquisizione e la scheda target (in questo caso la AMD Geode LX800).

Figura 1. Connessione della scheda di acquisizione dati per la misura dell’EnergyBench
Mentre la scheda target esegue la routine standard di misura, la scheda di acquisizione, pilotata da un trigger sincronizzato con la routine, acquisisce i livelli di tensione in modo da ricavare il consumo energetico medio per ogni singola iterazione. Allo stesso modo è possibile determinare anche il consumo minimo e massimo.
PERCHÉ NON FIDARSI DEI MIPS?
Non c’è dubbio che le prestazioni di un microcontrollore o un DSP vengano valutate in termini di tempo richiesto per l’esecuzione di un dato programma. Nei casi più comuni, in assenza di un sistema operativo che gestisce processi in multitasking, tale tempo coincide con il tempo di calcolo ovvero il tempo che il dispositivo dedica effettivamente al programma. Il tempo di calcolo TCAL può essere stimato dalla relazione:
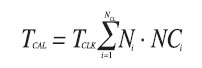
dove TCLK è il periodo di clock del processore, Ni è il numero di istruzioni di tipo i, NCi è il numero medio di cicli richiesto dalle istruzioni di tipo i e NCL è il numero di classi di istruzioni utilizzate nel programma. Il MIPS (milioni di istruzioni al secondo) è un indice di prestazioni indicato nei datasheet ma che dipende dalla frequenza del clock e può quindi risultare ingannevole. Si consideri infatti un processore che dispone di tre classi di istruzioni ciascuna delle quali richiede un diverso numero di cicli di clock come riassunto nella tabella 2.

Tabella 2. Classi di istruzioni e relativo numero di cicli per l’esempio considerato
Il programma di benchmark utilizzato per la misura delle prestazioni sarà quindi composto da varie istruzioni appartenenti alle varie classi. Il numero di istruzioni per ciascuna classe dipende dal compilatore dal momento che ciascun compilatore organizza il codice in modo diverso utilizzando un numero diverso di istruzioni distribuite nelle varie classi in modo differente. Per ipotesi si supponga che utilizzando due diversi compilatori la situazione sia quella di tabella 3.
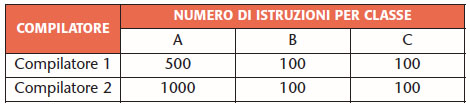
Tabella 3. Numero di istruzioni per classe ottenute con due compilatori diversi
Applicando la formula precedente per ricavare il tempo di calcolo nei due casi si ottiene:
Compilatore 1:
T1=TCLK·(500·1+100·2+100·3)=1000TCLK
Compilatore 2:
T2=TCLK·(1000·1+100·2+100·3)=1500TCLK
Dai risultati ottenuti risulta quindi che il codice ottenuto dal secondo compilatore ha un tempo di esecuzione più lungo del 50% rispetto al primo. Valutando invece l’indice MIPS nei due casi si ottiene:
MIPS1=10-6·(500+100+100)/(1000TCLK)=0,7FCLK·10-6
MIPS2=10-6·(1000+100+100)/(1500TCLK)=0,8FCLK·10-6
Come si può notare l’indice MIPS ottenuto per il secondo caso è maggiore del primo per cui il secondo codice sembrerebbe risultare più veloce in contrasto con quanto ottenuto precedentemente. Questo semplice esempio fa capire come l’indice MIPS possa essere risultare ingannevole. Considerare l’indice MIPS per confrontare due microcontrollori ha senso solo a parità di architettura e a parità di frequenza di clock. Nella figura 2 sono riportati due esempi di datasheet in cui l’indice MIPS può trarre in inganno. Nel datasheet del dsPIC30F210 il costruttore dichiara una velocità massima di 30 MIPS con FCLK=40MHz mentre nel datasheet del TMS320 il costruttore dichiara una velocità di ben 1333 MIPS, ma in questo caso FCLK=167MHz.

Figura 2. L’indice MIPS per alcuni dispositivi
LE SUITE SOFTWARE DELL’EEMBC
Come già accennato il consorzio EEMBC misura le prestazioni dei dispositivi utilizzando apposite suite software che sottopongono il micro a particolari operazioni a seconda dell’indice da ricavare. Ciascuna suite è costituita da diversi task ognuno focalizzato su una particolare prestazione. Di seguito sono descritte in dettaglio le varie suite con i relativi task.
AutoBench™
AutoBench™ è la suite dedicata alla misura dell’indice Automark™ ed è composta da 16 diverse prove:
- Angle-to-Time Conversion
Simula una applicazione embedded automotive in cui la CPU legge un contatore che misura il ritardo in real-time tra gli impulsi misurati da una ruota dentata posta sull’albero motore. La CPU calcola quindi il punto morto superiore dell’albero (TDC), calcola la velocità del motore ed opera una conversione degli impulsi ricevuti in una posizione angolare dell’albero. Il valore ottenuto è espresso in unità di tempo in modo lineare e relativo al TDC. L’algoritmo legge il valore attuale del contatore e lo sottrae dal precedente al fine di ricavare il tempo tra i due impulsi consecutivi. Se per qualche motivo il TDC non può essere calcolato. Il contatore continua ad essere incrementato fino a raggiungere il massimo valore (pari al numero di impulsi per giro) a notificare un giro completo dell’albero. Quando il TDC viene calcolato correttamente, il contatore viene azzerato. - Basic Integer and Floating Point Questo algoritmo misura le prestazioni sui calcoli in aritmetica intera e virgola mobile. Viene calcolata la funzione arcotangente usando la serie:
arctan(x)=x P(x2)/Q(x2) in cui P e Q sono due polinomi ed x varia tra 0 e π/4. - Bit Manipulation
È un test che simula un’applicazione che richiede la manipolazione di grandi quantità di bit. La routine simula una parte di un display a caratteri in cui un carattere viene fatto scorrere lungo una linea. Il buffer che costituisce la linea viene convertito in una serie di pixel in modo da mappare il carattere nella ROM del display. - Cache “Buster”
È un test che simula un’applicazione automotive priva di memoria cache. Evidenzia le performance in situazioni in cui vengono eseguite lunghe sezioni di codice di controllo con piccoli salti all’indietro o che utilizzano frequentemente gli stessi dati. - CAN Remote Data Request
Viene simulata un’applicazione in cui un nodo CAN scambia messaggi con il resto del sistema. In particolare viene simulata la situazione in cui un messaggio RDR (Remote Data Request) viene ricevuto da tutti i nodi CAN. Ciascun nodo deve quindi controllare l’identificatore del messaggio per capire chi è il destinatario. Se si riconosce come destinatario può inviare l’OK alla trasmissione del dato. - Fast Fourier Transform (FFT)
Viene effettuata una analisi spettrale di una forma d’onda variabile nel tempo. L’algoritmo opera una trasformata FFT su una serie di valori complessi memorizzati come parte reale e parte immaginaria su due diversi array. Una volta convertiti tutti i valori nel dominio della frequenza, viene calcolato lo spettro di potenza del segnale. - Finite Impulse Response (FIR) Filter
In questo test la CPU opera un fltraggio FIR su valori fixed-point a 16 o 32 bit. Il test prevede un filtraggio passa-basso e passa-alto sui dati di ingresso. - Inverse Discrete Cosine Transform (iDCT)
Questo test simula un’applicazione automotive in cui viene manipolata della grafica (riconoscimento immagini). Viene operata una trasformata inversa (iDCT) su una matrice di dati in ingresso utilizzando aritmetica intera a 64 bit. - Inverse Fast Fourier Transform
L’algoritmo opera una trasformata FFT inversa su una serie di valori complessi memorizzati come parte reale e parte immaginaria su due diversi array. - Infinite Impulse Response (IIR) Filter
L’algoritmo opera un filtraggio IIR su valori fixed-point a 16 o 32 bit. Il filtraggio è di tipo passa-basso e passa-alto. Questa prova consente di testare le prestazioni del dispositivo in operazioni di moltiplicazione con addizione ed arrotondamento. - Matrix Arithmetic
L’algoritmo opera una decomposizione LU di una matrice quadrata di ordine n passata in ingresso. Viene calcolato anche il determinante della matrice in ingresso ed il prodotto con una seconda matrice. - Pointer Chasing
Questo test permette di valutare il dispositivo nella gestione dei puntatori. L’algoritmo opera una ricerca in una lista doppia per trovare un determinato dato. Per manipolare l’intera lista viene ripetuta la ricerca per un grande numero di dati. - Pulse Width Modulation (PWM)
Viene simulata una applicazione in cui un attuatore viene pilotato in PWM in modo proporzionale ad un segnale di ingresso. L’algoritmo assume che il dispositivo piloti un motore attraverso un ponte H in entrambe le direzioni. Ad ogni passo viene simulato il segnale PWM e viene verificato se il motore ha raggiunto la posizione desiderata. - Road Speed Calculation
L’algoritmo in questo caso calcola la velocità su strada attraverso il calcolo della differenza tra due contatori. Questo test è un mix di routine aritmetiche e di controllo di flusso. In microcontrollori di fascia bassa le routine aritmetiche possono costituire un vero e proprio collo di bottiglia. - Table Lookup and Interpolation
È un test che mette in luce la prontezza di un dispositivo nel calcolo di valori. Vengono utilizzate tecniche di lookup per ottenere dati da una tabella di valori, quindi i valori ottenuti vengono interpolati per ricavare altri valori derivati. Un tipico esempio è il calcolo dell’angolo di iniezione in un motore a partire dalla coppia e dalla velocità del motore. - Tooth-to-Spark
Questo algoritmo è tipico nella gestione del carburante durante il processo di combustione in un motore. La CPU calcola l’apertura dell’iniettore in base alla velocità e alla coppia del motore.
CONSUMERBench™
La suite ConsumerBench™ consente di ricavare l’indice Consumermark™ che classifica un dispositivo in applicazioni consumer. La suite è costituita da quattro diversi test.
- High Pass Grey-Scale Filter
È uno degli algoritmi più utilizzati in applicazioni di image processing. Per ciascun pixel dell’immagine, viene calcolato un valore che coinvolge gli 8 pixel adiacenti usando un opportuno calcolo matriciale. Il test sottopone il dispositivo ad una grossa mole di calcoli (moltiplicazioni ed addizioni) oltre alla gestione di array piuttosto grandi. Il test viene operato su una immagine di 320x240 pixel. - JPEG
Il test opera una compressione/decompressione JPEG su una immagine campione di 320x240 in RGB ad 8 bit. Il risultato è una indicazione delle potenziali prestazioni del micro su una compressione/decompressione JPEG di una immagine fissa. - RGB to CMYK Conversion
Il test è molto utile in campo consumer in quanto l’algoritmo è quello tipicamente utilizzato nelle stampanti per convertire i dati provenienti dal PC, quindi in RGB, in CMYK. Per il test viene usata una immagine di 320x240 RGB ad 8 bit. - RGB to YIQ Conversion
La conversione da RGB a YIQ viene operata negli encoder NTSC in cui vengono ricavati i valori di luminanza e crominanza a partire dal segnale RGB. Questo test prevede un elevato numero di moltiplicazioni ed addizioni tra matrici.
DENBench™
Questa suite fornisce l’indice DENmark™ utile in applicazioni digital entertainment quali PDA, telefoni cellulari, lettori MP3, videocamere, DVD players/recorders, TV e sistemi multimediali in genere. La suite comprende dodici diversi test:
- AES
L’algoritmo implementa la cifratura AES utilizzata per la crittografia di numero di protocolli quali TLS, SSL, SSH e IPSEC. Il risultato del test indica le prestazioni del micro nelle operazioni di criptaggio e decriptaggio dei dati utilizzando questo algoritmo. - DES
È un test analogo al recedente ma implementa l’algoritmo DES anziché l’AES. - High pass gray-scale filters
È lo stesso utilizzato nella ConsumerBench™ suite. - Huffman Decoding
L’algoritmo di Huffman è molto utilizzato nella compressione JPEG ed MPEG nelle macchine fotografiche digitali. Il test misura le prestazioni del dispositivo sottoponendolo a operazioni di lookup, manipolazioni di singoli bit e trasferimenti all’interno della memoria. - MP3 Decode
Consente la misura delle prestazioni nella decodifica di file MP3 in applicazioni MP3 player. Il test implementa una decodifica del formato ISO 13818-3 MPEG-2 Layer 3 con frequenze di campionamento di 16KHz, 22,05 KHz o 24 KHz. - MPEG-2 Decode
Il test consiste nella lettura del file campione MPEG-2, lettura e interpretazione dell’header, lettura e decodifica dei dati. Una volta decodificati i dati vengono processati secondo quanto previsto nell’header quindi viene memorizzato un file .PPM in memoria e calcolato il valore del PSNR. - MPEG-2 Encode
L’algoritmo effettua una codifica MPEG-2 di un file .PPM memorizzato in RAM. Per la codifica vengono utilizzati gli algoritmo di Huffman e la trasformata iDCT. - MPEG-4 Decode
Il test utilizza l’implementazione di XviD di EEMBC per la codifica. La decodifica fornisce un file PPM. - MPEG-4 Encode
Questo test opera il processo inverso del precedente. Il risultato è un file MPEG-4. - RGB to CMYK Conversion
È lo stesso utilizzato nella ConsumerBench™ suite. - RGB to YIQ Conversion
È lo stesso utilizzato nella ConsumerBench™ suite. - RSA
RSA è un algoritmo di criptaggio dati simile all’AES. Il test utilizza una chiave privata per l’encryption.
NetworkingBench™
Della suite NetworkingBench™ ne esistono due versioni: una prevede tre tipologie di test e l'altra, invece, ne prevede 6. I tre test previsti dalla prima versione sono i seguenti:
- Open Shortest Path First
Implementa l’algoritmo di Dijkstra per la ricerca dei percorsi minimi. Tale algoritmo è utilizzato nei routers ed in molti altri accessori di rete. Il test utilizza due tabelle (una per i nodi ed una per gli archi) che vengono inizializzare ad ogni iterazione. - Packet Flow
Il test simula un router con 4 interfacce di rete. Viene inizializzato un buffer di dimensioni programmabili con datagrams per pacchetti IP. L’header è almeno di 20 byte ed alcuni contengono volutamente degli errori al fine di creare un log con un contatore di errori. I pacchetti vengono trasmessi e ricevuti in modo da creare un consistente flusso di dati. - Route Lookup
Implementa l’algoritmo di lookup (Patricia Tree) utilizzato nei router per la ricezione e la trasmissione di pacchetti IP. Il Patricia Tree è un particolare tipo di albero binario che permette ricerche veloci al suo interno. Il test crea un albero di questo tipo utilizzando indirizzi IP contenuti in un file di testo, quindi richiama una funzione di ricerca che sottopone il micro ad un carico di lavoro piuttosto pesante. L’efficienza della ricerca è proporzionale all’efficienza delle istruzioni CTI (Control Transfer Instructions) supportate dal dispositivo.
Nell'altra, invece, abbiamo i seguenti test:
- IP Packet Check
Questo test permette di valutare le performance del micro in un sistema router IP. È simile al Packet Flow della versione 1.0 con la differenza che nel processare i pacchetti viene fatto un check sulla lunghezza del pacchetto, sul checksum, la versione IP (IPV-4), la lunghezza dell’header. - IP Network Address Translator (NAT)
Il test esegue il meccanismo di NAT ovvero di trasferimento di pacchetti da una classe di indirizzi ad un’altra. Questo meccanismo è utilizzato nei firewall e nei router ed è completamente trasparente all’utente. - Open Shortest Path First
Il test è analogo a quello della versione 1.0. - Quality of service
Viene implementato un algoritmo di gestione della banda al fine di soddisfare i requisiti di QoS. Questo test prevede un uso intensivo della memoria per cui permette di valutare le prestazioni della cache, degli accessi in memoria e della latenza dei dati. - Route Lookup
È analogo a quello della versione 1.0. - Transmission Control Protocol
Permette di valutare le prestazioni di un dispositivo nella gestione di traffico TCP. Viene simulato un traffico caratteristico e tipico di trasmissioni server/client.
OABench™
Con i test di questa suite si ricava l’indice OAmark™ che caratterizza il dispositivo in ambienti di office automation. I test previsti sono tre: Dithering, Image Rotation e Text Processing.
- Dithering
Il test prevede la conversione di una immagine a scala di grigi in ua formato pronto per la stampa utilizzando l’algoritmo Floyd-Steinberg Error Diffusion. L’immagine di partenza è da 64K in scala di grigi ad 8 bpp, mentre l’immagine risultato è da 8K. Durante il processo vengono utilizzate due immagini buffer. - Image Rotation
Prevede la rotazione di 90° di una immagine bitmap. Durante questa operazione il dispositivo viene sottoposto a un ingente numero di operazioni bitwise, per cui l’indice che ne risulta è un buon indicatore della capacità di manipolazione dei singoli bit da parte del micro. - Text Processing
Questo test esegue un parsing di un file testo interpretando i caratteri come variabili, costanti e operatori. Questo tipo di operazione viene tipicamente usata nelle stampanti che interpretano il file da stampare come se fosse un file sorgente, quindi ne stampano il contenuto in accordo ai comandi contenuti nel file stesso.
TeleBench™
È la suite mediante la quale si ottiene l’indice Telemark™ che caratterizza il dispositivo in applicazioni di telecomunicazioni (tipicamente comunicazioni ADSL). La suite prevede cinque diversi test:
- Autocorrelation
Viene calcolata la funzione di autocorrelazione in aritmetica fixed-point di una sequenza di ingresso finita costituita da interi a 16 bit. Per il calcolo della funzione vengono impiegate molte operazioni di moltiplicazione, addizione e shift. - Bit Allocation
Questo test implementa l’algoritmo di Bit Allocation per modem DSL che usano tecnologia DMT. La modulazione DMT divide il canale in un grande numero di sottocanali indipendenti ciascuno caratterizzato da un proprio SNR. L’algoritmo Bit Allocation permette di ripartire i dati sui diversi canali. - Convolutional Encoder
Il test esegue un algoritmo di Convolutional Encoding e permette di conoscere le potenziali prestazioni dei micro in ambienti in cui questo algoritmo viene usato per la correzione di errore. - Fast Fourier Transform
È analogo a quello utilizzato dalla suite AutoBench™. - Viterbi decoder
Questo test permette di testare le capacità del micro nell’estrazione di un pacchetto dati da uno stream dati in ingresso in applicazioni embedded in cui si utilizza la codifica IS-136. Le operazioni cui il micro viene sottoposto sono: manipolazioni di singoli bit, confronti e lookup.
I MEMBRI DELL’EEMBC
Ecco un elenco di alcuni membri del consorzio EEMBC:


Le applicazioni embedded richiedono processori sempre piu’ performanti. Tool di questo tipo posso fornire informazioni sulle prestazioni complessive del sistema.