
Quali sono i limiti e le considerazioni da tenere presente quando si decide di fare il troubleshooting di un sistema embedded? E se poi la nostra applicazione risultasse integrata in un real-time kernel? In questo articolo cerchiamo di fare alcune considerazioni su come condurre sessioni di debug utilizzando la strumentazione a nostra disposizione.
Una sessione di test deve essere appositamente pianificata prevedendo tutti i possibili limiti o problemi che si possono presentare, in special modo, quando si deve condurre un’attività di verifica sul software embedded. In definitiva, occorre predisporre un’apposita metodologia per affrontare una sessione di test. Questa sessione è tanto particolare quanto più il sistema stesso non è corredato da un tool di debug o, ancora meglio, quando il tool non è stato acquistato per ragioni commerciali. L’utilizzatore di sistemi embedded ha una serie di strumenti a sua disposizione: da soluzioni commerciali a strumenti open, da sistemi costruiti come custom a metodologie che devono essere messe a punto a fronte di una serie attività preliminare.
Utilizzare sistemi Open
Tra i sistemi open sicuramente OpenOCD è uno strumento estremamente versatile, il sistema è stato messo a punto da Rath per interfacce TTY e GDB (il glorioso ambiente di debug della GNU). OpenOCD utilizza le prerogative già presenti su ARM (il microprocessore utilizzato da Rath): l’interfaccia e il protocollo JTAG. In ogni caso esistono anche soluzioni basate su differenti microcontrollori. Esiste un limite importante a questo tool: l’interfaccia JTAG non è presente direttamente su PC. Per questa ragione è necessario convertire i segnali del PC (seriale, parallela o USB) a dei valori accettati da OpenOCD. Esistono in commercio differenti schedine che permettono di svolgere questa funzione, o addirittura possiamo costruirci una nostra schedina. Utilizzare un GDB server su target è un compito abbastanza semplice per OpenOCD. Un debugger server permette alla sezione host di comunicare con il target attraverso un particolare protocollo chiamato RSP (Remote Serial Protocol), un protocollo orientato alla gestione dei messaggi. I mezzi trasmessivi utilizzati da questo protocollo sono diversi: da connessioni TCP alle banalissime seriali RS232. Il debugger GDB è un tool estremamente potente e utilizzato in ambiente embedded; è possibile controllare l’intero flusso di esecuzione di un programma attraverso l’uso di breakpoint o di esecuzioni in singola traccia, è possibile controllare l’evoluzione di ogni singola variabile o visualizzare e modificare locazioni di memoria. In questa configurazione la parte server del debugger è svolta da OpenOCD: in pratica l’host, o GDB client, comunica con la parte server (OpenOCD) secondo il protocollo RSP per condurre le sessioni di test. È chiaro che con OpenOCD, come server, si utilizzata sempre la porta JTAG: i comandi, che da lato host sembrano complessi (per esempio inserir e un breakpoint in memoria), si traducono in una serie di comandi inviati al processore attraverso JTAG. Forse qualcuno si ricorderà dei microprocessori Motorola 68332 o 68360 e l’uso, allora, abbastanza avveniristico delle soluzioni basate su BDM. I processori ARM, ARM7 o ARM9, dispongono di un’interfaccia particolare che consente di sopperire a varie funzionalità di debug: Embedded-ICE. In questo modo è possibile, con la nostra applicazione su memoria non volatile, svolgere sessioni di test e utilizzare le prerogative di breakpoint sul codice senza per questa ragione ricorre a spese, a volte, non indifferenti. È chiaro che per utilizzare un circuito del genere è necessario costruirsi una piccola scheda di interfaccia con una serie moduli software per sopperire alle varie attività di test.
Utilizzare un ICE (In-Circuit Emulator)
Un ICE racchiude in sé diverse componenti. È soprattutto una scheda con dei moduli software a corredo, sia sulla scheda stessa che su ambiente host, per condurre sessioni di test hardware e su software embedded. Uno strumento di questo tipo è sicuramente di enorme aiuto, ma, viceversa, risulta essere una soluzione abbastanza costosa. Un ICE è, grosso modo, una scheda hardware con un probe. Il probe è una piccola scheda che contiene il microprocessore stesso sotto test. Il probe deve essere piazzato sulla scheda target semplicemente sostituendo la CPU, per questa ragione il codice dell’applicazione embedded è posto in esecuzione senza problemi. Il sistema ICE deve essere, poi, corredato da una serie di moduli software. L’uso di un sistema di test di questo tipo permette di guadagnare in termini di prestazioni. Attraverso un ICE è possibile monitorare le linee dati e di indirizzo in questo modo diventa possibile costruire breakpoint particolari. Per esempio, è possibile definire un breakpoint, quando un definito indirizzo di memoria è acceduto quando un determinato valore (monitorando la linea dati) è scritto (o letto). Inoltre, l’ICE dispone di una memoria privata che, attraverso una serie di direttive, è possibile mettere a disposizione dell’ambiente target. Vale a dire che, in questo modo, è possibile discriminare porzioni di memoria target e porzioni interne (di ICE), per questa ragione, è permesso di forzare, da parte dell’ICE, gli accessi da esterni a interni (magari perché si sono scoperti problemi di accesso alle memorie del target). È possibile, inoltre, monitorare ogni ciclo di CPU. In questo modo diventa fattibile costruire dei buffer interni al sistema di test per controllare, in esecuzione, il comportamento del software sotto test. In questo modo, con la possibilità di registrare su una porzione di memoria privata (buffer) un certo numero di istruzioni, è possibile visualizzare la storia di una determinata sequenza di istruzioni in un particolare intervallo di temporale. Questo ambiente, poi, dispone anche di un’altra interessante prerogativa: un apposito linguaggio per trasferire i comandi utenti ai diversi moduli presenti. Un linguaggio di questo tipo ha una particolare sintassi, così con questa sequenza:
WHEN ADDRESS >= 102 && ADDRESS <=
204 && DATA > 9 && DATA < 12 THEN BREAK
si definisce un breakpoint che è attivato quando si accede ad un intervallo di indirizzi (da 102 a 104) e con un valore compreso tra 9 e 12. In definitiva, utilizzare un hardware esterno, insieme con una serie di moduli software di supporto, è una soluzione che dà indubbi vantaggi, anche se i costi aumentano considerevolmente: in questo caso è necessario, come sempre, stabilire il giusto compromesso. Un sistema di test del genere permette di scoprire le cause, per esempio, di un crash periodico di sistema. In questo caso può essere conveniente attivare un trace, per mezzo di una serie di comandi dell’ICE, che permetta di monitorare le linee di reset. Ad ogni occorrenza di reset, l’ICE registrerà, in un buffer di memoria, gli eventi associati. Leggendo, poi, successivamente il buffer sarà possibile determinare le varie istruzioni coinvolte e, di conseguenza, i vari moduli software.
Sessione di test senza un In-Circuit Emulator (ICE)
A volte, però, non è possibile utilizzare un sistema di test con hardware integrato. Può succedere, infatti, di avere componenti, o schede, ormai obsoleti e non più in produzione. In questo caso dobbiamo utilizzare altri approcci. Una prima soluzione è sicuramente quello di simulare porzioni di codice su host. In questo caso è necessario reperire un sistema di simulazione del nostro microprocessore. Un sistema del genere, però, non è in grado di provare i vari dispositivi hardware presenti sulla scheda, ma in ogni caso può darci delle indicazioni di massima sulla fattibilità del nostro algoritmo. Una volta terminata con successo la nostra simulazione, possiamo mettere su memoria non volatile la nostra applicazione e vedere il suo comportamento nel mondo reale. Un approccio di questo tipo deve essere svolta in maniera incrementale: è necessario integrare piccoli moduli e verificarne il loro comportamento. In questo caso è buona norma utilizzare, se disponibili, Led o altre indicazioni sullo stato del sistema (pin) per seguire in maniera trasparente il programma. Un’altra soluzione è quella di utilizzare un piccolo monitor residente con funzioni di lettura e scrittura in memoria, downloading del codice e con possibilità di singola traccia e breakpoint. Una soluzione del genere è possibile solo se si ha una linea di comunicazione (per esempio una seriale Rs232) e una quantità di memoria per contenere il monitor stesso. Questo monitor può essere scritto appositamente per la nostra applicazione o possiamo verificarne se esiste una soluzione open per la nostra architettura. Il listato 1 mostra una porzione di un monitor per coldfire. Il monitor può essere testato per la maggior parte su host con un simulatore. Personalmente, anni fa ho messo a punto un monitor basato su PowerPc utilizzando la versione demo del simulatore della casa costruttrice SingleStep.
brcom
clr.l prec_cmd
move.b #2,flag_cmd
bsr getch
cmpi.b #$0d,d0
beq exit_brcom
cmpi.b #$2b,d0 +
beq brpls
cmpi.b #$2d,d0 -
beq brmin
bra syntax_err
exit_brcom
bsr flush_a
rts
brpls move.b #3,flag_cmd
bsr getnuma
move.l d0,add_br
bset.b #2,twf
ori.w #$8000,_sr
bclr #$1,bkptf
MESSAGE ‘Break on rom ‘,bmsg1234
MESSAGE ‘at address ‘,bmsg1235
MESSAGE_INT d0
MESSAGE_LINE
bra exit_brcom
brmin bclr #2,twf
andi.w #$7fff,_sr
MESSAGE ‘Disable Break on rom ‘,bmsg2323
MESSAGE_LINE
bra exit_brcom
| Listato 1 - breakpoint in ROM |
Sessione di test senza un monitor
Possiamo anche realizzare un ambiente di test senza un monitor. In questo caso, se fosse disponibile una Rs232, possiamo basare la nostra applicazione di debug sulle funzioni di I/O, come printf con sequenze di inline breakpoint. Non si tratta delle modalità di inline breakpoint presenti in ambito Intel o PowerPc. Nel caso Intel è possibile richiedere un breakpoint inline attraverso l’istruzione asm { int 3 }, o con PowerPc con un’istruzione di trap o system call, sc n. Il concetto di inline breakpoint è abbastanza semplice e il listato 2 mostra un esempio.
void Inline_Breakpoint(int x)
{
int cmd;
if (x == 0) return;
for (;;) {
printf(“\n > “);
scanf(“%d”, &cmd);
switch (cmd) {
/* Di seguito per ogni commando ….. */
}
}
}
| Listato 2 - inline breakpoint |
La funzione di inline breakpoint è attivata inserendo la funzione “Inline_Breakpoint(x)” nelle porzioni del codice. In questo caso si associa un parametro alla funzione con una variabile globale, che può essere 0 o 1 a seconda del comportamento richiesto. Con un valore pari a 0, la modalità di debug è disattivata, viceversa con 1. L’idea è di inserire la modalità di inline breakpoint alla locazione desiderata e di cambiare il valore del parametro. Per esempio, possiamo inserire un inline_breakpoint “inline_breakpoint (pippo)” in vari punti del codice, in questo modo con un valore pari a 1 è abilitata la funzione e, al momento di ciascuna attivazione, viene eseguito il codice corrispondente.
Sessione di test con un trace buffer
La figura 1 mostra uno schema di questa soluzione.
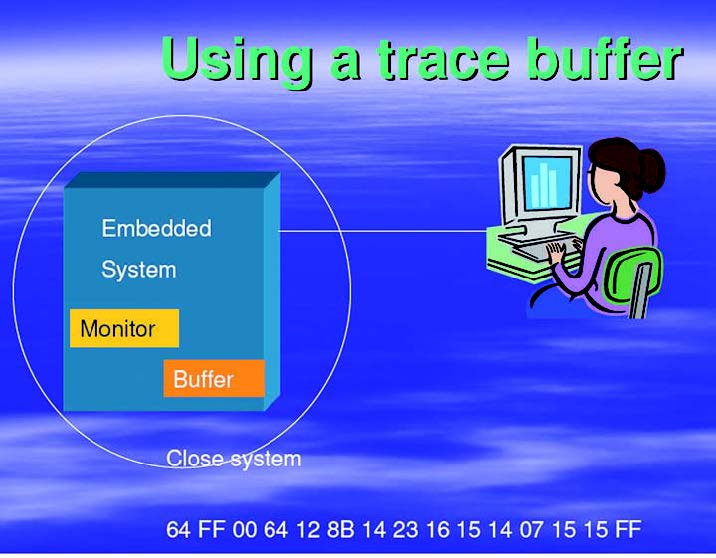
Figura 1: Trace buffer.
In pratica si tratta di inserire codice di monitoring all’interno della nostra applicazione embedded e registrare in un buffer di memoria (di ampiezza di alcuni kbyte) il flusso del programma con dei codici identificativi che segnalano in maniera univoca i vari moduli software che sono attraversati. La figura mostra un possibile codice 64 che potrebbe identificare il modulo del gestore degli eventi asincroni e con dei successivi valori che evidenziano i comportamenti all’interno del modulo (lettura, scrittura di particolari valori di memoria).
Sistemi SoC
Altre considerazioni possono essere fatte per le soluzioni basate su SoC. In questo ambiente l’osservazione, e le sessioni di test, condotte su un single-core può risultare insufficiente. Per questa ragione per applicazioni di questo tipo si cercano di privilegiare le attività di debugging svolte in ambito multi-core. In questo caso vanno privilegiati l’approccio dell’osservazione massima, cioè la massima tracciabilità di ciascun core e del bus interno.
