
Questo articolo rappresenta la seconda e ultima Puntata della serie "L’architettura ARM big.LITTLE" per la Rubrica Firmware Reload di Elettronica Open Source.
IL SISTEMA
Per realizzare una soluzione big.LITTLE impeccabile occorre prendere in considerazione anche il sistema che ruota attorno ai processori. Un componente chiave è sicuramente rappresentato dal modulo di interconnessione CCI-400 (si osservi la Figura 1), in grado di agevolare la completa coerenza tra il Cortex-A15 e il Cortex-A7, come anche la coerenza degli I/O relativi ad altri componenti come una GPU.
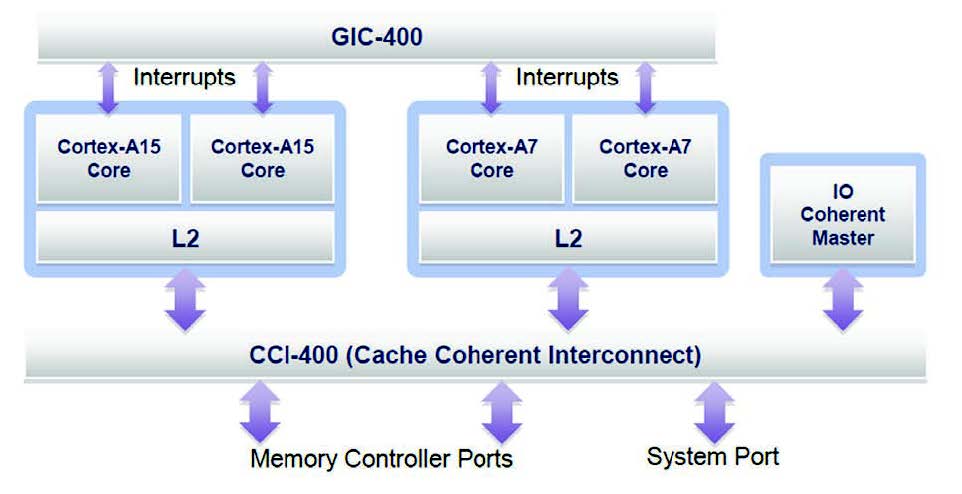
Figura 1: Il sistema di interconnessione coerente
Ottimizzando le transazioni dei processori Cortex-A15 e Cortex-A7 e riconsiderando opportunamente i cammini tra la memoria principale e il sistema, si può arrivare a ottenere una soluzione in grado di offrire il massimo valore di performance. Un altro componente fondamentale dell’architettura big.LITTLE è il controllore generico di interrupt condiviso (GIC- 400). Esso non solo è in grado di distribuire fino a 480 interrupt ai processori Cortex-A15 e Cortex-A7, ma permette anche agli interrupt di essere migrati tra un qualunque core del Cortex-A15 o del Cortex-A7. Per quanto riguarda l’attività di trace e debug, entrambi i processori Cortex-A15 e Cortex-A7 sono in grado di offrire delle ottime soluzioni per il trace, e sono entrambi compatibili con l’architettura Debug v7.1. Il supporto completo all’attività di debug e trace per il sistema big.LITTLE avviene attraverso il SoC CoreSight. Un ultimo punto da tenere in considerazione è che ogni sistema big.LITTLE che include i processori Cortex-A7, Cortex-A15, CCI-400 e GIC-400 è adatto a tutti i tipi di applicazioni big.LITTLE. Non esiste alcuna caratteristica di configurazione o di ottimizzazione che possa favorire una particolare applicazione. Tuttavia, al fine di ridurre la complessità software nella migrazione big.LITTLE, è consigliabile implementare lo stesso numero di core sui cluster Cortex-A15 e Cortex-A7.
IL MODELLO BIG.LITTLE
Nel modello di migrazione dei task dell’architettura big.LITTLE, il sistema operativo e le applicazioni sono sempre eseguiti o sul processore Cortex-A15 oppure sul Cortex-A7, mai su entrambi i processori nello stesso tempo. Questo modello è la naturale estensione del DVFS (Dynamic Voltage and Frequency Scaling), che indica i punti operativi delle attuali piattaforme per dispositivi mobili in grado di fare in modo che un sistema con singolo processore applicativo sia in grado di garantire il livello di prestazioni richieste dalle applicazioni. Nel caso dell’architettura big.LITTLE, questi punti operativi saranno applicati sia al Cortex-A15 sia al Cortex-A7; quando il processore Cortex-A7 sta lavorando, il sistema operativo può impostare i punti operativi esattamente come farebbe per una piattaforma con un singolo processore applicativo. Quando poi il processore Cortex-A7 raggiunge l’apice del suo processing ed è necessario incrementare ulteriormente la capacità di elaborazione, viene attivata la migrazione dei task, la quale prende il controllo del sistema operativo e delle applicazioni e li sposta sul processore Cortex-A15, dotato di una capacità di calcolo superiore. Questo meccanismo permette di eseguire sul processore Cortex-A7 le applicazioni che richiedono una bassa o media capacità di calcolo, raggiungendo un livello di efficienza energetica altrimenti non ottenibile se le stesse applicazioni fossero eseguite sul processore Cortex- A15. Quest’ultimo, per contro, potrà occuparsi delle applicazioni di elevata intensità di elaborazione, cioè quelle richieste dagli smartphone e dai dispositivi portatili di ultima generazione. In Figura 2 è mostrato un interessantissimo grafico che mette a confronto i due processori dell’architettura big.LITTLE per quanto concerne il tradeoff tra prestazioni e assorbimenti di potenza. Si noti come le due curve caratteristiche dei processori siano quasi continue, consentendo di selezionare l’uno o l’altro sulla base delle specifiche esigenze di prestazioni o di consumi.
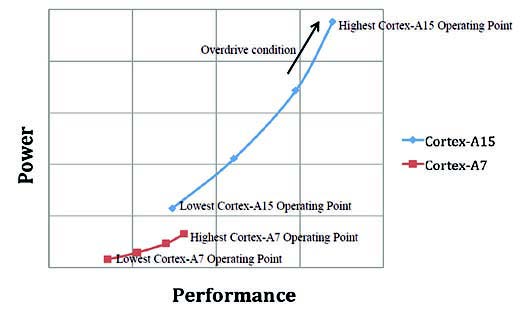
Figura 2: Performance vs. assorbimenti
Un importante aspetto del sistema big.LITTLE riguarda il tempo richiesto per migrare un’applicazione tra il Cortex- A15 e il Cortex-A7. Se questo tempo diventa troppo elevato, potrebbe intervenire il sistema operativo e il sistema potrebbe prevalere, per un certo periodo, rispetto ai benefici prodotti dalla migrazione dei task. Proprio per questo motivo, il sistema è progettato in modo tale da essere in grado di migrare in meno di 20.000 cicli, cioè 20 microsecondi nel caso di processori operanti alla frequenza di 1 GHz. Uno dei motivi per cui la migrazione dei task può essere così veloce è che le informazioni di stato del processore coinvolte nella migrazione dei task sono molto ridotte. Il processore che sta per essere disattivato, chiamato "processore in uscita", deve avere precedentemente salvato il contenuto di tutti i registri integer e Advanced SIMD, oltre allo stato completo della configurazione CP15. Il processore che sta per essere attivato per l’esecuzione, chiamato "processore in entrata", dovrà recuperare lo stato memorizzato dal processore in uscita. Inoltre, ogni interrupt attivo controllato dal GIC-400 deve pure essere migrato. Per eseguire il salvataggio e il recupero dello stato sono richieste meno di 2.000 istruzioni, e poiché i due processori sono identici dal punto di vista architetturale, esiste una corrispondenza diretta (uno-a-uno) tra i registri di stato nei processori in entrata e in uscita. In Figura 3 è illustrato il processo di migrazione tra i processori inbound ("in entrata") e outbound ("in uscita").
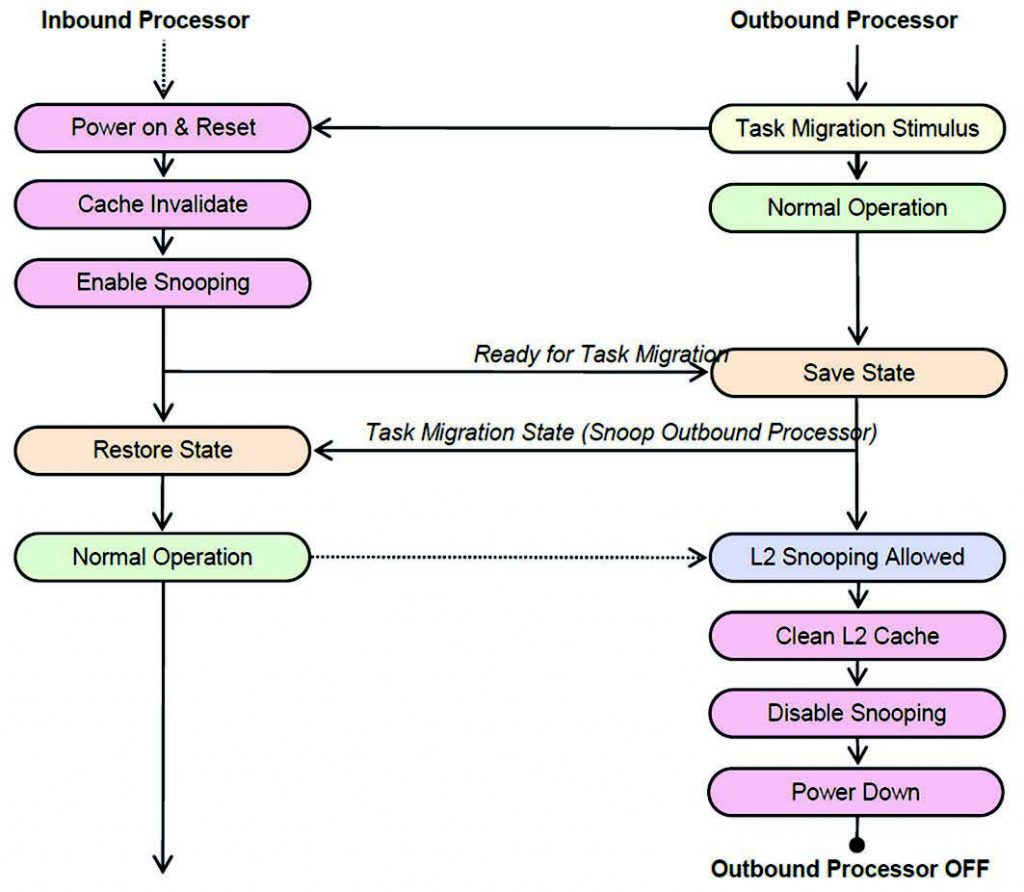
Figura 3: La migrazione dei task
La coerenza è chiaramente un fattore cruciale per ottenere un tempo di migrazione ridotto, in quanto permette allo stato salvato sul processore outbound di essere intercettato e ripristinato sul processore inbound anziché passare attraverso la memoria principale. Inoltre, poiché la cache di livello 2 del processore outbound è coerente, essa può rimanere alimentata dopo la migrazione dei task in modo tale da migliorare il tempo di riempimento della cache del processore inbound, intercettando il valore dei dati. Comunque, visto che la cache di livello 2 del processore outbound non può essere allocata, questa potrà essere ripulita e disattivata in modo tale da ridurre gli assorbimenti. Occorre inoltre osservare come, durante la migrazione, l’esecuzione dei thread avvenga regolarmente, fatta eccezione per il breve periodo di "blackout" durante il quale gli interrupt sono disabilitati e lo stato è trasferito dal processore outbound a quello inbound.
IL MODELLO BIG.LITTLE MP
Poiché il sistema big.LITTLE è totalmente coerente grazie alla presenza del modulo CCI-400, un altro possibile modello logico di utilizzo è quello che permette ai processori Cortex-A15 e Cortex-A7 di essere attivati e abilitati all’esecuzione contemporanea del codice. Questo modello viene chiamato big.LITTLE MP ed è essenzialmente un sistema Multi-Processore di tipo eterogeneo. In questo modello, il processore Cortex-A7 esegue di default il codice, mentre il Cortex-A15 viene attivato (e quando ciò avviene, esso lavora in contemporanea con l’altro) solo se vi sono thread che richiedono un livello di performance da giustificarne l’utilizzo. Il sistema big.LITTLE MP è notevole, in quanto permette di mandare in esecuzione i thread sulla risorsa che è più appropriata. I thread che richiedono un’elevata capacità di elaborazione e tempi di risposta molto ridotti (si pensi al caso di un’interfaccia utente) possono ad esempio essere allocati sul Cortex-A15. I thread che invece fanno un largo uso dell’I/O o che non producono dei risultati con criticità temporale possono essere eseguiti sul Cortex-A7.
IL SOFTWARE
Come parte del sistema big.LITTLE, ARM fornisce un commutatore software da utilizzarsi con il Cortex-A15, Cortex-A7, CCI- 400, e GIC-400. Il commutatore svolge due compiti primari. Il primo compito è fornire tutti i meccanismi richiesti per attuare la migrazione dei task tra il Cortex-A15 e il Cortex-A7. Ciò include il salvataggio e il ripristino dello stato del processore, il codice richiesto per portare dentro e fuori dallo stato di coerenza i processori, l’intercettamento dei dati sull’interconnessione e la migrazione degli interrupt. Il commutatore può essere utilizzato così com’è, oppure si può utilizzare il relativo codice come template per l’integrazione nel sistema operativo. Il secondo compito è quello di nascondere al sistema operativo l’esiguo numero di differenze a livello di modello programmativo tra il Cortex-A15 e il Cortex-A7. Nonostante i due processori siano architetturalmente identici, e tutti i registri siano letti e scritti con una modalità architetturalmente equivalente, il contenuto dei registri stessi potrebbe non essere sempre identico. Ad esempio, il contenuto del registro Main ID che identifica il particolare processore, assumerà un valore diverso nel caso di Cortex-A15, rispetto al caso di Cortex-A7, come pure il contenuto dei registri CP15 che descrivono le topologie delle cache di livello 1 e 2. Fortunatamente, entrambi i processori Cortex-A15 e Cortex-A7 implementano le estensioni della virtualizzazione e pertanto gli accessi a questi registri eseguiti dal sistema operativo possono essere intercettati dal livello di hypervisor, proprio dove il commutatore software può gestirli.
CONCLUSIONI
Abbiamo illustrato in questo articolo in che cosa consiste il sistema big.LITTLE e quali sono le sue possibili applicazioni. Da notare che quello presentato, basato sui processori Cortex-A15 e Cortex-A7, è il primo sistema della serie, ma altri lo seguiranno in futuro. Nelle piattaforme per applicazioni mobili basate su un singolo processore, il software deve gestire, spesso con una certa complessità, i differenti carichi di lavoro richiesti da task con valori anche molto differenti di performance. Il vantaggio del sistema big.LITTLE è aprire le porte a un’implementazione estremamente performante del Cortex-A15, dal momento che questo verrà alimentato e attivato solo quando questo livello di performance è effettivamente richiesto. Si riesce così a sfruttare pienamente l’elevata efficienza energetica del Cortex-A7, il vero cavallo di battaglia dell’architettura. In conclusione, attraverso il sistema big.LITTLE è possibile aumentare le prestazioni e nel contempo allungare la durata delle batterie, due fattori determinanti per lo sviluppo delle applicazioni mobile di prossima generazione.

Vuoi scoprire tutti i segreti della programmazione ARM?
Scegli il corso "ARM-Programmazione e Progettazione" di EOS-Academy
