
La sempre più prepotente diffusione di sistemi multicore pone in evidenza il problema di una programmazione dedicata. La domanda è: sarà facile o difficile scrivere software per sistemi multicore? Proviamo a rispondere.
Lo sviluppo crescente di piattaforme multicore rappresenta per l’industria del software un’opportunità e allo stesso tempo un problema. C’è chi ritiene che tutto il codice vada revisionato e riadattato, chi invece sostiene che il codice già scritto venga correttamente interpretato dai moderni sistemi operativi SMP (Symmetric Multi-Processing) e dalle librerie di threading. La promessa delle piattaforme multicore per i sistemi embedded è quella di portare una riduzione dei consumi di potenza; tuttavia ciò può essere ottenuto solo se le applicazioni sequenziali attualmente esistenti vengono riprogettati per sfruttare i vantaggi del parallelismo. La maggior parte delle piattaforme multicore attualmente sul mercato (ARM, MIPS) hanno da 2 a 4 core, sfruttati adeguatamente da sistemi operativi full SMP come Linux. Questo permette agli ingegneri di sfruttare immediatamente il vantaggio dei core aggiuntivi, semplicemente facendo lavorare più di un programma alla volta, lasciando al sistema operativo i dettagli. Combinando questo con tecniche di clock scaling o di power gating su ogni core non utilizzato, la potenza consumata diminuisce notevolmente. Per permettere dunque che alla stessa frequenza di clock il numero di applicazioni elaborate aumenti è necessario un intervento sul codice. Il sistema operativo semplifica la vita fornendo un supporto consolidato al multithread e delle API (in particolare le POSIX Threads, Pthreads) che permettono agli ingegneri di parallelizzare agevolmente del codice sequenziale oltre ad accedere a tutte i benefici delle applicazioni multithread disponibili come open-source. Una volta che il programma è stato parallelizzato, il sistema operativo si preoccuperà di distribuire a runtime i thread ai core disponibili, senza intervento dello sviluppatore.
PORTING DI UN CODICE SEQUENZIALE SU PIATTAFORMA MULTICORE
La difficoltà di rielaborare il codice per sfruttare a pieno il parallelismo dipende dalla singola applicazione. Parecchie applicazioni si possono tuttavia considerare facilmente modificabili, per esempio quelle riguardanti comunicazioni o networking, applicazioni dove un singolo programma deve dialogare con molti e diversi canali di iterazione. Un esempio potrebbe essere il software riportato di seguito (figura 1), tipico top level per un’applicazione server.

Figura 1: listato del top level di una
applicazione server.
Il codice mostra come la gestione del multithread possa essere semplice, ogni connessione in entrata genera un thread che permane per tutta la durata della connessione, i thread non hanno necessità di comunicare tra loro, così il sistema operativo li assegna ad un processore e ne pianifica l’esecuzione. Fin qui tutto bene, tuttavia non sempre capita di avere un’applicazione che utilizza le API multithreading senza scambio di dati tra i thread, anzi spesso capita il contrario. In applicazioni come la processazione di segnale i tread sono frequentemente intrecciati e la richiesta di ridurre i consumi di potenza, e di conseguenza la frequenza di clock, è sentita. Soprattutto per bilanciare il consumo di area dovuto alla presenza di più di un core. Convertire codice gia altamente ottimizzato in sottoattività destinate a singoli thread può non essere facile. Il listato in figura 2 mostra un codice che processa un insieme di dati complessi.

Figura 2: esempio di codice facilmente
parallelizzabile.
Ogni iterazione del ciclo è indipendente dalla successiva poiché la chiamata della funzione process(...) accede al singolo dato dell’array ma non agli altri. In questo caso con una piattaforma a quattro core ci aspetteremmo almeno una velocizzazione del processo di almeno un 3x. Il limite terorico di 4x non è raggiungibile per gli overhead che accompagnano la gestione dei thread. Il listato di figura 3 mostra come sia possibile parallelizzare l’implementazione utilizzando Pthreads.

Figura 3: codice parallelizzato ma inefficiente.
Il codice è piuttosto illeggibile, tuttavia qualcosa è comprensibile, il main loop ora elabora i dati a passi di PROCESSOR_COUNT (in questo caso 4). Ogni iterazione genera un insieme di thread e attende la loro conclusione con pthread_join prima di proseguire con l’iterazione successiva. Quando andiamo ad applicare questo codice su un target multicore, le performance sono inferiori a quelle che ci si attendeva, comunque superiori all’implementazione sequenziale ma non di molto. Questa è la tipica situazione che giustifica la reputazione attribuita alla programmazione multicore particolarmente difficile. Infatti è necessario spendere tempo per indagare la causa del problema, sarà un’inefficienza della libreria di threading o una non corretta comprensione della sequenzialità degli eventi? Per fortuna ci aiutano i software di analisi per i sistemi multicore. La possibilità di catturare e rappresentare graficamente l’esecuzione dei thread evidenzia subito tre problemi (figura 4).

Figura 4: rappresentazione grafica dell’esecuzione dei thread del codice di figura 3
Per prima cosa buona parte del tempo di esecuzione viene dedicato alla chiamata della libreria di gestione dei thread, poi la durata della funzione utente di processazione dei dati varia il proprio tempo di esecuzione (probabilmente non tutti i dati sono trattati allo stesso modo). Infine si evidenzia il problema del bilanciamento del lavoro dovuto alla presenza di soli quattro thread, quando un core ha finito il compito assegnato rimane in attesa senza niente da fare. Il primo problema è abbastanza comune per chi è agli inizi ma può essere facilmente identificato da chi è più esperto, verificando il numero di thread che si creano. Una crescita esagerata del numero di thread diventa un problema. La soluzione è di creare un numero fisso di thread elaboratori detti spesso thread pool, l’implementazione è legata alla singola applicazione, in generale comunque questi continuano ad esistere e lavorano in cooperazione o sotto il controllo di un thread gestore, finché determinate condizioni non si verificano. A questo punto il gestore può chiuderli e il programma principale proseguire. Per il secondo problema individuato, ossia la variabilità del tempo di esecuzione della processazione dei dati, probabilmente si può ipotizzare che alcuni elaborazioni sui dati siano state ottimizzate e quindi risultino più veloci. Per esempio utilizzando lookup tables che velocizzano il codice anche se ne incrementano le dimensioni. Questo può essere un bene per sistemi sequenziali ma nei sistemi multicore risulta spesso un problema, possiamo vedere dalla figura 4 che tre core rimangono in attesa che il quarto completi le operazioni. La soluzione è fornire del lavoro ai core in attesa, gli sviluppatori devono permettere ad ogni thread di procedere con ulteriori dati appena terminati quelli elaborati, senza attendere come avviene attualmente la chiamata della pthread_join(...). Abbinare il numero di thread al numero di core raramente è una buona idea, sia per i problemi visti nell’esempio, sia perché si limita la scalabilità dell’applicazione. In figura 5 è possibile osservare le variazioni operate sul codice per ottimizzare la processazione.

Figura 5: codice di figura 3 ottimizzato.
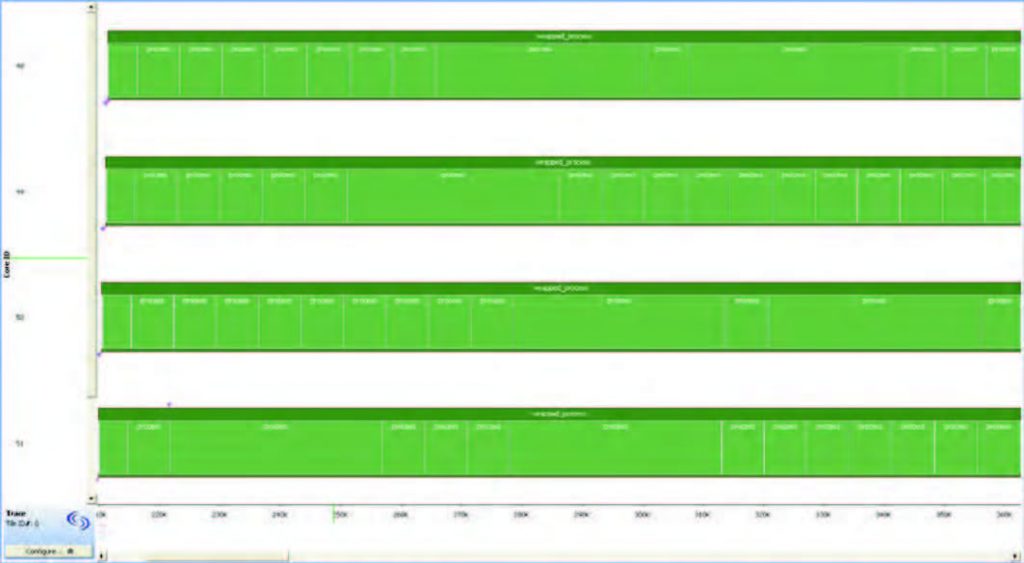
Figura 6: rappresentazione grafica dell’esecuzione dei thread del codice di figura 5.
Il cambiamento più drastico è la rimozione del loop di controllo ad alto livello, sostituito da un loop nella funzione wrapped_process(..). Questo si traduce in un incremento delle variabili coinvolte nel loop tra i thread, con la conseguente necessità di aggiornare gli indici correttamente. Attraverso la variabile condivisa gDataIndex sappiamo gli indici dei dati processati, tuttavia è necessario proteggere la variabile da accessi multipli per evitare data race. Si realizza tutto ciò attraverso una variabile mutex incapsulata in una funzione fetchAndIncrementIndex(...). Il risultato è visibile in figura 6, adesso ci si avvicina ad un accelerazione delle operazioni di 4x. Ovviamente quelli riportati in precedenza sono esempi, lo sviluppo di un software multicore è molto più complesso e problematico. In un ciclo semplice come quello descritto in precedenza è stato necessario apportare delle modifiche per sfruttare a pieno il multicore, figuriamoci con un ciclo dove le variabili dipendono dall’iterazione precedente.
FUNZIONERÀ DAVVERO?
Ogni volta che si modifica un codice funzionante esiste la possibilità di introdurre degli errori, e questo è tanto più vero quanto più l’intervento è esteso. La ricerca del parallelismo porta alla possibile introduzione di errori, quando un programma è sequenziale certe considerazioni vengono prese per scontate. La più importante di queste, è che il codice venga eseguito nell’ordine in cui è scritto, quando le attività sono divise tra più processori questa assunzione non è più valida. Si consideri la situazione dove una parte di programma che lavora su un processore modifichi il valore di una variabile. Ora si immagini un secondo processore che legga questa variabile, che valore verrà letto? Dipenderà dal momento della lettura, se precedente o posteriore al processo di scrittura operato dal primo processore. Questa situazione è detta data race, entrambi i processi sono in competizione per accedere alla variabile. Questo problema è ben conosciuto da chi abitualmente programma in multithread, tanto che esistono molte tecniche per controllare gli accessi ad una variabile ed evitare che più thread accedano contemporaneamente. In ogni caso sarà sempre il programmatore che dovrà implementare una qualsiasi di queste tecniche e non sempre è immediato valutare su quali variabili utilizzarle e ancor meno individuare un problema generato da un problema di data race. Ritornando all’esempio di figura 5, il codice protegge l’accesso alla variabile globale gDataIndex con una funzione che garantisce un accesso sicuro dei thread attraverso un mutex. In più viene restituita una copia della variabile in maniera che ogni modifica non alteri l’originale. Questo modo di operare è alla base di una buna programmazione in ambito multithread per arrivare a minimizzare la possibilità di inserire bug nel codice. In aiuto al programmatore esistono dei tool software che consento di identificare possibili problemi di data race. Questi tool rimangono ad osservare gli accessi in memoria eseguiti dal programma a run time (figura 7).

Figura 7: strumento software che evidenzia un possibile data race.
Se sono individuati conflitti di accesso tra thread diversi, sono subito segnalati come possibili problemi sempre che non vengano identificati meccanismi di sincronizzazione (tipo mutex). Sfortunatamente non tutti i casi di data race sono rilevati dai tool di analisi perciò la soluzione migliore è utilizzare un approccio metodico, individuando le variabili condivise e analizzandone il contenuto per stabilire se devono essere protette da un mutex (per garantire l’atomicitità delle operazioni), o se richiedono cambiamenti più radicali nel codice. L’altro problema enorme della programmazione a thread sono i deadlocks. Possono capitare quando due risorse protette hanno un accesso nello stesso istante, tutto funziona se la protezione è richiesta nell’ordine giusto, nel caso di ordine sbagliato il sistema si ritrova in una situazione di halt (listato di figura 8).

Figura 8: codice passibile di deadlock.
Due funzioni sono eseguite da thread diversi. Se un thread raggiunge function_in_thread_1 per prima ed esegue entrambe le protezioni prima che il secondo thread esegua la protezione in function_in_thread_2, allora tutto lavora correttamente. Il secondo thread sarà in attesa sulla risorsa in attesa che diventi disponibile. Se invece entrambi i thread raggiungono le rispettive funzioni nello stesso istante allora diventa un problema. Entrambi i thread eseguono la prima protezione, ma quando procedono con la seconda entrambi si accorgono che l’altro processo sta lavorando sulla variabile e nessun thread viene portato a conclusione, bloccando l’intero sistema. Anche in questo caso i tool ci vengono in aiuto evidenziando possibili problemi di deadlock ma è difficile dare per certo se una determinata sequenza può provocare un blocco oppure no. La soluzione è puntare su una programmazione il più standardizzata possibile, scegliendo di utilizzare librerie dette di lock management per fornire delle API a tutti i programmatori che lavorano su un progetto.
CONCLUSIONI
Da quanto discusso appare chiaro che i multicore sottopongono nuove sfide ai programmatori software. Esiste codice facilmente portabile, per tipologia, su multicore, altro che necessita di un intervento più sostanzioso. Nel caso embedded la maggior parte di software richiede delle modifiche. Tutto il codice pensato per sistemi sequenziali è stato nel corso degli anni ottimizzato per aumentarne la velocità, un porting su sistemi multicore ne mina sia la correttezza che la sicurezza. Per fortuna gli strumenti software a supporto dei programmatori aiutano ad individuare possibili problemi. Questi tool però necessitano di addestramento e soprattutto deve cambiare la mentalità del programmatore che deve imparare ad utilizzare API pensate per il multicore. Un numero sempre maggiore di risorse diventano disponibili per il mondo del multicore, questo contribuisce ad evitare che i programmatori soccombano nella gestione dei loro sistemi multithread. A questo punto la domanda conclusiva, programmazione multicore, facile o difficile? La risposta è, sicuramente, dipende, pero grazie agli strumenti e alle metodologie gia esistenti ed in sviluppo almeno non è impossibile.


Ho già provato con successo a scrivere delle piccole routines in multicore con il linguaggio D. Se il linguaggio aiuta, in questo senso, il programmatore deve faticare meno e vi sono anche meno probabilità che il programma si blocchi. E’ davvero un argomento molto critico.