
Questo articolo descrive alcune tecniche utilizzabili per stimare correttamente lo spazio di stack in applicazioni embedded. Tali stime possono essere utilizzate per evitare il fenomeno dello stack overflow, frequente causa di malfunzionamenti applicativi. L’articolo presenta inoltre alcune tecniche di ottimizzazione dello stack per sistemi embedded con e senza RTOS, con particolare riferimento alla condivisione dello stack utilizzata nei sistemi operativi ERIKA Enterprise ed in generale nei sistemi operativi di classe OSEK/VDX.
COSA È LA MEMORIA DI STACK?
La memoria comunemente denominata stack è una zona di memoria utilizzata per memorizzare variabili automatiche, variabili temporanee, ed indirizzi di ritorno salvati al momento della invocazione delle subroutines. La memoria stack è tipicamente organizzata come una struttura dati a pila, di cui il microcontrollore mantiene l’indirizzo di cima (tos, top of the stack) in un registro ad hoc. La pila viene utilizzata tramite due istruzioni assembler, denominate PUSH e POP: l’operazione di PUSH si preoccupa di salvare un valore all’interno della pila (tipicamente un registro); l’operazione di POP si occupa di recuperare un valore precedentemente salvato. La memoria di stack viene tipicamente riservata in modo statico all’interno di una applicazione. Essa non è mai completamente occupata: la memoria realmente utilizzata varia a tempo di esecuzione e dipende dalle chiamate innestate di funzioni C in un dato istante di esecuzione. In generale, è possibile stimare a runtime la quantità di memoria di stack massima utilizzata in un esperimento. Per implementare tale funzionalità, è sufficiente al momento del boot inizializzare la memoria di stack con un pattern noto, per poi verificarne la persistenza a tempo di esecuzione. Alcuni debugger commerciali, forniscono un supporto automatico per questa funzionalità (vedere Figura 1).

Figura 1: stima dello stack effettuata con debugger Lauterbach Trace32 e supporto ORTI per ERIKA Enterprise
Nei sistemi a microcontrollore il dimensionamento della memoria di stack è particolarmente critico per due motivi. Il primo motivo è dovuto alla scarsità di memoria RAM: se si considerano le dimensioni di memoria offerte da molti microcontrollori, si può notare come la dimensione della memoria RAM è notevolmente inferiore rispetto alla dimensione della memoria Flash (o ROM). Ad esempio, la Figura 2 mostra una foto di un chip utilizzato per applicazioni di riconoscimento sonoro. Nella foto, si può notare come lo spazio occupato sul silicio da RAM e ROM è praticamente identico nonostante la dimensione della RAM (512 bytes) sia molto inferiore alla dimensione della ROM (12 Kbytes).
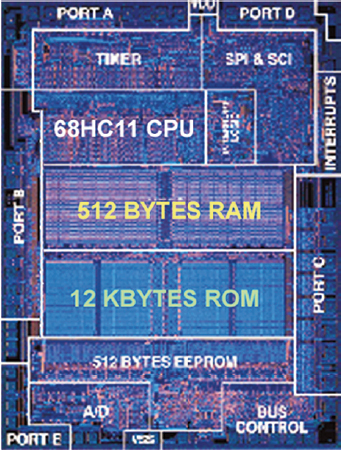
Figura 2: circuito integrato per riconoscimento sonoro. Notare la diversa area allocata per RAM e ROM
Il secondo motivo è legato al fatto che un errato dimensionamento dello stack può portare ad un cosiddetto “stack overflow”, situazione particolarmente difficile da replicare e testare che spesso provoca il sollevamento di una eccezione critica del processore (ad esempio, il Microchip dsPIC DSC ha un registro denominato SPLIM che può essere utilizzato per generare eccezioni quando la cima della pila supera un dato valore). Diventa pertanto importante, nei sistemi a microcontrollore, essere in grado di ridurre e stimare il caso peggiore di utilizzo di memoria RAM da dedicare allo stack nell’applicazione finale.
STIMA E RIDUZIONE DELLO STACK IN ASSENZA DI UN SISTEMA OPERATIVO
La dimensione dello stack in sistemi embedded senza sistema operativo dipende dalla dimensione degli stack frame che il compilatore alloca per ogni chiamata di funzione. In tal caso, l’utilizzo dello stack dipende dalla quantità di variabili locali allocate (molti sistemi riescono ad allocare parte delle variabili locali all’interno di registri), e dal numero di chiamate di funzione innestate presenti a tempo di esecuzione. Per ridurre la dimensione totale necessaria per lo stack, si possono utilizzare tecniche che prevedono:
- l’abolizione delle chiamate di funzione ricorsive (che tipicamente necessitano di molte invocazioni di funzioni innestate e quindi molto stack);
- la scelta attenta della struttura del codice per evitare un numero di invocazioni di funzioni innestate troppo elevato;
- l’utilizzo di tecniche di inlining del codice che evitano di generare il codice di prologo ed epilogo delle funzioni che tipicamente fa uso di stack per il salvataggio dell’indirizzo di ritorno.
È necessario comunque ricordare che l’ottimizzazione dello stack deve essere il più possibile mirata alla riduzione dei picchi massimi di utilizzo dello stack, che si verificano tipicamente solo in situazioni particolari, e non di una ottimizzazione generalizzata di tutte le funzioni applicative. Per comprendere al meglio l’utilizzo massimo dello stack di una particolare funzione possono essere utilizzati tool commerciali che permettono, tramite una analisi astratta del codice (ovvero senza una sua esecuzione), di derivare il caso peggiore della occupazione di memoria di una zona di codice. Un’altra tecnica che porta alla riduzione della memoria utilizzata dallo stack è quella di analizzare le varie funzioni richiamate nel caso peggiore per spostare eventuali variabili locali allocate nello stack in variabili globali. Questa tecnica in realtà non porta ad una riduzione di per se della memoria RAM utilizzata, ma porta allo spostamento della allocazione di dati da una zona di memoria ad un’altra, azione utile se il microcontrollore in uso ha limitazioni sulla dimensione massima dello stack (ad esempio, nel microcontrollore Infineon C167 solo una piccola parte della memoria può essere dedicata al system stack).
STIMA E RIDUZIONE DELLO STACK IN PRESENZA DI UN SISTEMA OPERATIVO
L’utilizzo di un RTOS all’interno di sistemi embedded è spesso collegato alla necessità di avere più attività concorrenti implementate in altrettanti task del sistema operativo. La quantità di stack necessaria per il funzionamento dei sistemi operativi dipende fondamentalmente dall’algoritmo di scheduling implementato. Se il sistema operativo permette una schedulazione non preemptive, in generale esiste la possibilità che in una particolare implementazione i vari task possano condividere uno stesso stack (in tal caso, infatti, al più un task alla volta sarà in esecuzione nel sistema). Nel caso dei sistemi preemptive, in generale occorre prevedere uno stack separato per ogni task. In altre parole, la memoria totale utilizzata per lo stack del sistema è costituita dalla somma dello spazio di stack allocato per ogni singolo task, più quello necessario per la gestione degli interrupt. Lo spazio di stack potrà pertanto essere calcolato utilizzando la seguente formula:
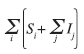
dove per ogni task ti viene considerato lo spazio di stack Si più, sempre per ogni task, lo spazio Ij richiesto dalla somma di tutti gli interrupt innestati che in generale vengono allocati sullo stesso stack del task in esecuzione al momento dell’arrivo del primo interrupt. Come vedremo nei prossimi paragrafi, sono possibili varie ottimizzazioni volte alla minimizzazione dello stack. Tali ottimizzazioni richiedono una modifica alla semantica delle primitive del sistema e sono basate sulla condivisione dello stack tra task diversi.
Ottimizzazione dello stack dedicato agli interrupt
La prima tipologia di ottimizzazione riguarda la gestione degli interrupt. In particolare, in molti sistemi operativi per microcontrollori gli interrupt vengono gestiti in modo tale da riabilitare la gestione degli interrupt a più alta priorità durante la esecuzione dello handler. Tale gestione degli interrupt viene detta ad interrupt “innestati”, ovvero interrupt ad alta priorità possono fare preemption sull’interrupt in servizio, al fine di minimizzare il tempo di risposta di eventi asincroni ad alta priorità. In questi casi sono possibili due ottimizzazioni: la prima consiste nell’abolire la possibilità di gestire interrupt innestati, limitando in questo modo lo spazio da riservare agli handler. Lo stack utilizzato dal sistema si riduce pertanto a:
![]()
Tale soluzione non è sempre attuabile in quanto può comportare tempi di bloccaggio elevati nell’esecuzione degli interrupt a più alta priorità. La seconda ottimizzazione prevede l’allocazione di uno stack per la gestione degli interrupt innestati: all’arrivo del primo interrupt, il sistema effettua un cambio di pila su di uno stack separato. In questo caso, si ha il vantaggio di supportare interrupt innestati riservando uno spazio totale pari alle necessità di ogni task ti sommate alle necessità degli interrupt, con il costo a tempo di esecuzione di poche istruzioni assembler necessarie per il cambio di puntatore di pila e per il conto del numero di handler in esecuzione. Le formule in questo caso diventano:
![]()
oppure:
![]()
a seconda se si applichi solo la seconda od entrambe le ottimizzazioni proposteõ
Condivisione dello stack tra task
La seconda tipologia di ottimizzazione porta a considerare i casi in cui ci possa essere condivisione dello stesso stack. In generale, lo stack può essere condiviso tra attività diverse quando si può garantire che non ci sia interleaving tra le esecuzioni dei vari task. Ovvero, non può mai accadere una esecuzione di due task a “zig-zag” come è descritto nel punto a) della Figura 3, in cui è disegnato un generico algoritmo di scheduling (ad esempio, potrebbe essere un algoritmo a timeslicing tipo Round-Robin, comunemente utilizzato nei sistemi operativi general-purpose, oppure uno scheduler prioritario con l’utilizzo di semafori bloccanti).
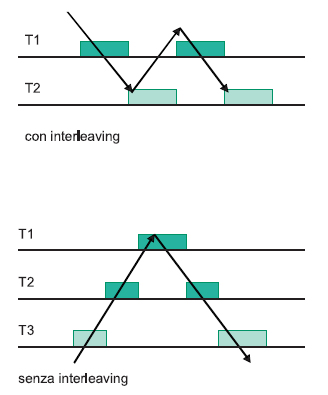
Figura 3: esecuzione dei task con bloccaggi o revoca, o con preemption
Il caso b) il sistema non ha interleaving, in quanto il task a priorità più bassa non si blocca ma viene solo preemptato da un task più importante, che termina prima che il task a bassa priorità possa eseguire di nuovo. Per garantire una esecuzione dei task senza interleaving è necessario abolire tutte le chiamate a primitive bloccanti all’interno dei task.
Ovvero, in altre parole le primitive del sistema non possono offrire servizi di attesa temporizzata (ad esempio, sleep()), né di sincronizzazione esplicita (ad esempio, sigwait(), sem_wait()), né di mutua esclusione implementata tramite bloccaggi (ad esempio, pthread_mutex_lock(), sem_wait()). Il risultato di tale modifica semantica è un sistema in cui i task una volta partiti non si possono mai bloccare: i task potranno essere solo preemptati da task a priorità più alta. Questi sistemi tipicamente utilizzeranno come algoritmo di scheduling un algoritmo a priorità fisse con Immediate Priority Ceiling, in cui è possibile gestire la condivisione delle risorse come esecuzione ritardata non bloccante. In particolare, la struttura dei task passa da un modello “bloccante”, in cui i task di fatto sono costituiti da un ciclo infinito che implementa tipicamente l’azione che il task deve realizzare (ad esempio, una lettura di un sensore) ad un modello “one-shot”, in cui i task esistono dall’inizio del sistema, e vengono solamente attivati esplicitamente quando necessario. Al termine dell’esecuzione il task non muore, ma libera il proprio stack per permettere ad altri task di eseguire sul medesimo spazio di memoria. Nei task one-shot, le informazioni che mantengono lo stato del task in modo persistente (indicate nei listati come persistent) diventano variabili globali, e la parte di inizializzazione viene spostata al momento della inizializzazione del sistema. Inoltre, non esiste più una funzionalità di end_instance(), in quanto il task una volta terminato libera lo stack da lui occupato. I task “one-shot” possono condividere uno stesso stack: in mancanza di primitive bloccanti, i task non si sospendono mai ed al termine di ogni istanza liberano lo spazio di stak utilizzato, proprio come al termine di una chiamata di una normale funzione C.La struttura dei task oneshot, per le sue caratteristiche e le sue possibilità di condividere lo stack, è stata utilizzata dal consorzio OSEK/VDX per la implementazione dei Basic Tasks, che appunto sono task concorrenti schedulati con un algoritmo a priorità fissa senza possibilità di utilizzo di primitive bloccanti.
Lo standard OSEK/VDX propone anche un’altra categoria di task, gli Extended Task, disponibile solo nelle conformance class ECC1 ed ECC2, che possono invocare la primitiva bloccante WaitEvent(), che implementa di fatto un punto di sincronizzazione bloccante. Gli Extended task hanno una struttura simile ai task con modello “bloccante”. Un sistema operativo (come ERIKA Enterprise in configurazione “monostack”) che implementa solo task one-shot utilizzando il protocollo Immediate Priority Ceiling ha la proprietà di poter implementare un solo stack per tutti i task e per tutti gli interrupt. In questo caso, nel caso di interrupt innestati, l’occupazione totale di stack sarà di:
![]()
dove:
![]()
Non tutti i sistemi operativi supportano direttamente i task one-shot. Se in particolare il sistema operativo utilizzato non supporta tale semantica, è sempre possibile implementare una condivisione dello stack “emulata”, raggruppando varie funzionalità che sarebbero state allocate in task diversi all’interno di uno stesso corpo. In tal caso, la attivazione dei task potrà avvenire utilizzando delle condizioni booleane che permettono di mettere in esecuzione per costruzione una sola funzionalità alla volta, implicitamente implementando una condivisione di stack.

Articolo molto interessante e molto tecnico. E’ bello finalmente vedere degli articoli dove spiegata bene la differenza fra stack e heap, e andar poi piu’ nel profondo sullo studio dello stack.
Ho potuto anch’io lavorare col LauterBach, pero’ i costi sono proibitivi purtroppo.