
Uno schedulatore è certamente il cuore di un sistema che si definisce real-time. Quali sono le ragioni per cui un sistema possa definirsi real-time? Come un sistema real-time svolge il proprio ruolo? Quali sono gli algoritmi di schedulazione utilizzati in un sistema di questo tipo? Un sistema può essere hard real-time o soft real-time ma, in ogni caso, occorre definire regole ben precise per utilizzare correttamente la CPU.
Introduzione
Quando ero uno studente universitario, un mio professore era sovente fare la domanda “… entro quanto tempo deve rispondere un sistema per definirsi real-time?” e le risposte erano sempre varie: c’era chi rispondeva “un sistema è real-time se la risposta ad un evento è dell’ordine di microsecondi”, ma c’era anche chi, come me, rispondeva “ dipende… dipende da quanto è real-time un sistema…”: è per questo che il mondo real-time si divide in due grandi filoni: hard real-time e soft real-time. In una computazione real-time (come nella vita) il tempo è tutto e chi gestisce la risorsa tempo in un sistema è certamente lo schedulatore. Questo fornisce l’algoritmo per determinare quale task deve essere messo in esecuzione e quando. Lo scopo di questo articolo è di dare indicazioni sui vari algoritmi di schedulazione real-time e di mostrare come lavora uno schedulatore. Tralasciamo per il momento il concetto di task, risorsa condivisa o quant’altro. Parlare di task è, anche questo, un argomento vasto e complesso che comprende i concetti di task deterministici e true deterministici, di context
switch, di dispatcher. Il mondo real-time sarà esplorato in successivi articoli.
PANORAMA SUGLI ALGORITMI DI SCHEDULAZIONE
In un mondo reale occorre gestire sofisticate applicazioni. Quando parliamo di flight control o di controllori di robot o anche di applicazioni mediche, allora descriviamo dei sistemi certamente complessi dove la risorsa tempo ha un peso rilevante. L’intenzione di questo articolo è di fare il punto su alcuni algoritmi di schedulazione proposti e adottati in applicazioni reali. Certamente, chi utilizza algoritmi di schedulazione deve sapere in quale mondo deve essere adattato. Per ogni applicazione esiste un suo algoritmo, difficilmente un algoritmo di schedulazione va bene per ogni applicazione. Se facciamo una classificazione allora dobbiamo identificare il mondo reale, infatti esistono applicazioni e algoritmi per sistemi distribuiti, monoprocessori e multi-processori. Esistono task periodici o aperiodici (sporadici). Esistono anche algoritmi di schedulazione studiati per gestire correttamente risorse condivise. O anche, algoritmi di schedulazione dove un fattore importante è rappresentato dall’uso della priorità, cioè quando le priorità nel sistema sono statiche o dinamiche.
POLITICA DI SCHEDULAZIONE
Lo schedulatore, come già detto, è lo strumento che determina quale task deve essere messo in esecuzione. Oggi, la maggior parte delle soluzioni commerciali, implementano due comuni algoritmi:
- preemptive basato sulla priorità
- round-robin
La maggioranza delle applicazioni commerciali utilizzano gli algoritmi round-robin o preemptive basato sulla priorità, questo per svariate ragioni: primo per la facilità implementativa e, secondariamente, per degli standard impliciti commercialmente consolidati. C’è poi chi implementa propri algoritmi di schedulazione, ma questo filone va pian piano scomparendo. Vediamo sommariamente le caratteristiche di questi due algoritmi.
Preemptive basato sulla priorità
Dei due algoritmi, il più utilizzato è l’algoritmo pre-emptive basato sulla priorità. Questa è la tipica strategia che permette ai processi di essere temporaneamente sospesi (preemptive scheduling) che si contrappone all’altra strategia chiamata anche run-to-completion. Quest’ultimo filone è chiamato anche non-preemptive scheduling (schedulazione senza prerilascio). Il comportamento dell’algoritmo con prerilascio (preemptive scheduling) è schematizzato in figura 1, dalla figura si vede che il task che viene posto in esecuzione è quello con la priorità più alta nel sistema.
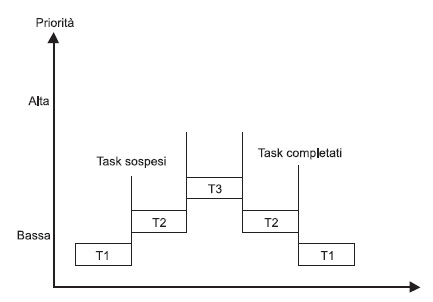
Figura 1. Schematizzazione del preemptive basato sulle priorità
I task con la priorità più bassa vengono messi, per così dire, nella coda “ready-to-run”. Quanta granularità deve avere la priorità in un sistema? Le priorità in un sistema possono essere, per esempio, di 256 livelli di priorità o anche di 15, dipende dal sistema RTOS in gioco. In questo senso, poi, di solito la priorità più bassa viene individuato nel valore 0, mentre quella più alta in 256 o 15. Il concetto che sta alla base di questo ragionamento è il seguente: ogni task ha una priorità, contenuta nella sua TCB, Task Control Block, e la priorità più alta determina quale task deve essere messo in esecuzione per prima. Può succedere che un task, con una priorità più alta rispetto al task corrente in esecuzione, viene messo nella coda “ready-to-run”: in questo caso lo schedulatore provvede a salvare il contesto del task corrente e, poi, si occupa di cambiare il contesto con il primo task nella coda di ready. Questo particolare meccanismo è evidenziato nella figura 1, in cui vediamo che il task 1 viene sospeso a beneficio del task 2, che a sua volta viene poi sospeso a beneficio del task 3. I task sospesi vengono messi in una coda apposita che potrebbe adottare, per esempio, una politica FIFO. In seguito, non appena i tasks sospesi sono pronti ad essere messi di nuovo in esecuzione si evidenzia un processo inverso: il task 3 viene sospeso a beneficio del task 2 che viene posto in esecuzione, a sua volta il task 2 viene sospeso a beneficio del task 1. Il ragionamento di tutto questo si basa sul meccanismo della priorità, una priorità è un numero che ha una valenza importante: infatti, quel numero ne determina la frequenza della sua esecuzione. La priorità può essere statica, nel senso che viene assegnata al momento della creazione del task e non più modificabile, o dinamica, in questo caso è possibile, dinamicamente, cambiare la priorità del task utilizzando delle apposite chiamate di sistema. Esistono diverse scuole di pensiero sulla dinamicità della priorità. La possibilità di cambiare la priorità da maggiore flessibilità al sistema e permette all’applicazione di mutare il suo comportamento in base agli stimoli esterni a cui è sottoposta. Al contrario c’è chi critica questa scelta: cambiare priorità al task potrebbe creare anomalie nel sistema e introdurre comportamenti disattesi.
Round-Robin
Il principio di questa politica di schedulazione è che ogni task dispone di un quanto di tempo di CPU per svolgere il proprio compito. Applicare l’algoritmo di round-robin in un sistema reale è abbastanza utopistico. In un sistema real-time possono esistere task con vari gradi d’importanza e, per esempio, in un round-robin classico non esiste il concetto di priorità. Se nell’impostazione classica alla fine del quanto di tempo assegnato ad un processo questo risulta ancora in esecuzione, allora lo schedulatore assegna la CPU ad un altro processo interrompendo il processo corrente. L’approccio di tipo round-robin può essere adottato, per esempio, in un sistema preemptive basato sulla priorità con un sistema fatto di task di uguale priorità. Il comportamento di un algoritmo di questo tipo è mostrato in figura 2.
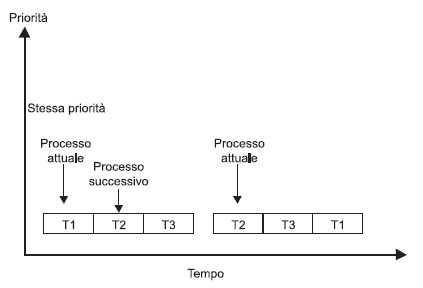
Figura 2. Il comportamento dell’algoritmo Round-Robin
Uno schedulatore round-robin non è difficile da implementare. Occorre mantenere una lista dei processi eseguibili e ad ogni tick di sistema si decrementa, il quanto associato al processo. Quando questo tempo associato si esaurisce, il processo viene messo in coda alla lista dei task ready-to-run e il “quanto di tempo” viene riassegnato. Una questione importante in sistemi di questo tipo è la giusta definizione di un quanto di tempo. Oggi però si tende ad associare l’algoritmo round-robin con una schedulazione basato su priorità: ogni processo ha una sua priorità e l’esecuzione spetta al processo a priorità più alta. In questo modo quando un processo viene sospeso da un task più prioritario, il suo contatore viene congelato ed è posto in esecuzione il processo con priorità più alta. Non appena il task sospeso è di nuovo pronto all’esecuzione, allora viene ricaricato il suo contatore (quanto di tempo). Come i processi, in un sistema a prerilascio, i task vengono posti in esecuzione? In un sistema a schedulazione con priorità, in linea teorica, un task potrebbe controllare in maniera indefinita la CPU. Ma questo, in realtà, non avviene. Il task con priorità maggiore potrebbe, per esempio, decidere di sospendersi in attesa di eventuali sincronismi e in questo caso lo schedulatore pone in esecuzione il primo processo in attesa. Oppure, lo schedulatore stesso potrebbe decidere, ad ogni ticks del sistema, di decrementare la priorità del processo corrente: in questo caso, non appena il processo in attesa assume una priorità maggiore di quello in esecuzione avviene uno scambio di contesto. Questo è grosso modo lo scenario degli algoritmi di schedulazione, ma in un mondo che definiamo real-time le cose cambiano leggermente.
ALGORITMI NEI SISTEMI IN TEMPO REALE
Un sistema può essere hard o soft real-time, un sistema è definito hard se viene garantito che l’esecuzione di un’operazione non ecceda un preciso limite temporale, chiamato deadline. Per questo il tempo è importante ed è fondamentale in un sistema real-time: la predicibilità di un sistema real-time è di primaria importanza per attivare la correttezza temporale degli eventi. Il termine real-time non è un sinonimo di veloce ma di predicibile (predictable): un sistema predicibile deve conoscere i limiti temporali delle proprie azioni. In questo articolo esaminiamo alcuni modelli quali il rate-monotonic (RM), earliest deadline (EDF), least-laxity dynamic (LLF) e per ultimo il maximum-urgency-first (MUF). Per affrontare in dettaglio l’argomento è necessario fare alcune considerazioni:
- Un task viene messo in esecuzione, in maniera ripetitiva, secondo un tempo definito: il periodo.
- Un task deve concludere la sua esecuzione prima dell’inizio del suo successivo periodo: cioè un task deve concludersi prima della sua deadlines.
- Un task non deve sincronizzarsi con altri task
- Un task può essere interrotto, in qualsiasi punto della sua partizione temporale.
- Un task non si sospende volontariamente: cioè non usa meccanismi quali delay o simili.
Queste sono alcune delle considerazioni da tenere presenti. Come abbiamo detto, poi, un algoritmo di schedulazione può essere statico o dinamico, a secondo che si possa o meno alterare la priorità dei processi. In questo caso, ci sono algoritmi di schedulazione che vanno bene per un mondo statico e altri per uno dinamico.
Rate-monotonic
Questo algoritmo si basa sugli studi di Liu e Leyland del 1973. Il rate-monotonic è il più famoso e utilizzato algoritmo di schedulazione per il mondo real-time. L’elemento fondamentale di questo algoritmo è applicabile solo per sistemi real-time con eventi periodici e che non condividono risorse tra di loro. Esistono implementazioni di questo tipo in diversi linguaggi e applicazioni. In questo sistema si assegna la più alta priorità al task a più alta frequenza e la più bassa priorità al task a più bassa frequenza. Lo schedulatore pone in esecuzione sempre il task a più alta priorità. Il rate monotonic è un algoritmo statico: nel senso che non è possibile alterare la priorità dei task del sistema in maniera dinamica. Quando un processo dovrà essere schedulato, lo schedulatore prenderà il processo a più alta priorità interrompendo, eventualmente, il processo corrente. Gli autori dell’algoritmo esprimono con una relazione matematica la condizione secondo cui un insieme di task incontrano sempre la loro deadlines, la relazione è la seguente:
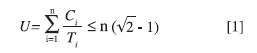
Ci è il tempo di esecuzione del task, Ti è il periodo e n è il numero dei task. La relazione [1] mostra il limite del 100% per un task fino al 69% per un insieme arbitrario di task e un valore dell’88% rappresenta una stima realistica. I valori di questo limiti sono riassunti in tabella 1.
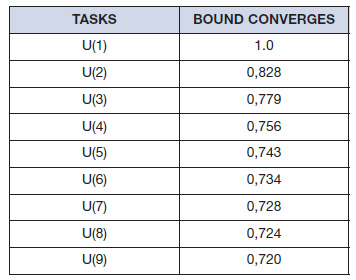
Tabella 1. Scheduling bounds
Un insieme di n task indipendenti e periodici possono essere schedulati da questo algoritmo solo se viene soddisfatta la relazione [1].
Earliest deadline
Questo algoritmo pone in esecuzione il task che incontra per primo la sua deadline: il task con la più prossima deadline ha così la più alta priorità. Mentre il task con la sua deadline più lontana ha una priorità inferiore. La più vicina deadline, nel sistema, cambia con il tempo perché questo algoritmo è di tipo dinamico. Nei sistemi periodici la deadline coincide con il periodo del processo.
Minimun-laxity-first
L’algoritmo di questo tipo assegna un elemento che chiamiamo “laxity” ad ogni task nel sistema, in seguito si seleziona il task con il minimo grado di laxity. La laxity viene definita come la differenza tra il tempo restante al processo prima del superamento della sua deadline e il tempo ancora necessario per terminare l’elaborazione.
Maximum-urgency-first
Il MUF è stato sviluppato al CMU (Carnegie Mellon University). Il maximum-urgency-firts è un algoritmo di tipo misto: è una combinazione di priorità fissa e dinamica. Per funzionare lo schedulatore MUF svolge alcune funzioni:
- Ordina i tasks come il rate monotonic
- Definisce un insieme di task critici
- Assegna un fattore di criticità a tutti quei task che sono definiti in un insieme critico
- 4. Assegna una priorità definita user ad ogni task
Queste sono alcune delle considerazioni da tenere presenti. Come si è detto, un algoritmo di schedulazione può essere statico o dinamico, a seconda che si possa o meno alterare la priorità dei processi. In questo caso, ci sono algoritmi di schedulazione che vanno bene per un mondo statico e altri per uno dinamico. Nella tabella 2 è riportato il tipo di priorità applicata a ciascun algoritmo di schedulazione.
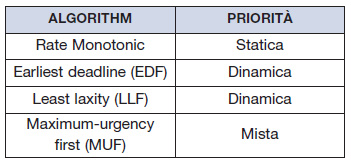
Tabella 2. Priorità per algoritmi
CONCLUSIONE
Siamo così giunti al termine. Abbiamo affrontato alcuni aspetti sugli algoritmi di schedulazione e abbiamo visto quelli adottati in un sistema a tempo reale. Questo lavoro non vuole esaurire l’argomento, ma ne rappresenta un’introduzione data la complessità in gioco. Un aspetto da approfondire è lo scheduling per analizzare in dettaglio altre tecniche di schedulazione con i loro comportamenti e gli aspetti di schedulazione in sistemi reali e le relazioni tra le diverse implementazioni



Il primo concetto importante nei sistemi real time è proprio la divisione tra hard e soft. Nel primo caso i vincoli sono molto restrittivi (safety-critical) a differenza del secondo. La rapidità di risposta di un sistema è legato anche al fatto di mantenere un certo sincronismo con altri sistemi per un tempo idealmente infinito.